DeepSeek R1: Complete Guide to the Open Reasoning Model
DeepSeek R1 is an open reasoning model from DeepSeek built to handle complex math, coding, logic, and multi-step problem-solving tasks. Released on January 20, 2025, DeepSeek R1 attracted attention because it made strong reasoning performance available through open model weights, a technical report, distilled variants, web access, and API access. DeepSeek’s official release described the model as MIT licensed and positioned its math, code, and reasoning performance as comparable with OpenAI o1.
This guide explains what DeepSeek R1 is, how it works, why it matters, how it compares with DeepSeek R1-Zero and closed models, how to run DeepSeek R1 locally, and when developers should consider using it.
Important 2026 API note: DeepSeek R1 remains an important open-weight reasoning model family, but DeepSeek’s current hosted API model IDs are
deepseek-v4-flashanddeepseek-v4-pro. The legacy namesdeepseek-chatanddeepseek-reasonercurrently route to V4 Flash modes and are scheduled for retirement after July 24, 2026, 15:59 UTC.
Table of Contents
Quick Facts About DeepSeek R1
| Item | Details |
|---|---|
| Developer | DeepSeek |
| Release date | January 20, 2025 |
| Model family | Reasoning model |
| Main architecture | Mixture-of-Experts |
| Total parameters | 671B |
| Activated parameters | 37B |
| Context length | 128K |
| Main license | MIT License for the DeepSeek-R1 code repository and model weights |
| Main variants | DeepSeek-R1, DeepSeek-R1-Zero, DeepSeek-R1-Distill models, DeepSeek-R1-0528 |
| Distilled model bases | Qwen2.5 and Llama 3 series |
| Main strengths | Math, code, logical reasoning, complex problem solving |
| Local deployment options | Hugging Face weights, Ollama, vLLM, SGLang, and compatible serving stacks |
DeepSeek lists both DeepSeek-R1-Zero and DeepSeek-R1 as 671B-parameter models with 37B activated parameters and a 128K context length. The same repository lists the six distilled checkpoints based on Qwen and Llama families.
What Is DeepSeek R1?
DeepSeek R1 is a large language model designed specifically for reasoning-heavy tasks. In simple terms, it is built to spend more effort on problems that require several steps: solving equations, debugging code, analyzing logic, comparing options, or working through structured technical questions.

A general chat model is often optimized for broad conversation, writing, summarization, and instruction following. A reasoning model like DeepSeek R1 is optimized to work through difficult prompts where the path to the answer matters. That does not mean it is always better than a general-purpose model. It means its design and training emphasize tasks where structured problem solving is especially important.
DeepSeek’s model card describes DeepSeek-R1-Zero as a model trained through large-scale reinforcement learning without supervised fine-tuning as a preliminary step. It also explains that DeepSeek R1 was introduced to address R1-Zero’s repetition, readability, and language-mixing problems by incorporating cold-start data before reinforcement learning.
Why DeepSeek R1 Matters
DeepSeek R1 matters because it brought advanced reasoning capabilities into a more open ecosystem. Instead of only offering a closed hosted model, DeepSeek released model weights, a technical report, distilled versions, and commercial-use permissions under MIT terms for the R1 series.
That openness has several practical implications.
First, developers can inspect, deploy, fine-tune, distill, or benchmark DeepSeek R1 in ways that are not possible with many closed models. The GitHub repository states that the code repository and model weights are MIT licensed and that the DeepSeek-R1 series supports commercial use, modification, derivative works, and distillation. It also clarifies that the distilled Qwen and Llama models inherit considerations from their upstream base model licenses.
Second, DeepSeek R1 made reasoning-focused distillation more visible. DeepSeek used reasoning data generated by the larger model to fine-tune smaller dense models. These distilled models are not equivalent to the full 671B model, but they make R1-style reasoning patterns more accessible to developers with smaller hardware budgets.
Third, DeepSeek R1 helped push open reasoning models into mainstream developer workflows. The release page described website access, API access, distilled models, and open access to model outputs for fine-tuning and distillation.
DeepSeek R1 vs DeepSeek R1-Zero
DeepSeek R1-Zero and DeepSeek R1 are closely related, but they are not the same model.
DeepSeek R1-Zero was the research experiment that showed strong reasoning behaviors could emerge from large-scale reinforcement learning without supervised fine-tuning as a preliminary step. It demonstrated behaviors such as self-verification, reflection, and long chain-of-thought style reasoning. However, it also had practical weaknesses, including endless repetition, poor readability, and language mixing.
DeepSeek R1 was the refined release. It incorporated cold-start data before reinforcement learning and used a more complete training pipeline designed to improve readability, user alignment, and general task usefulness while preserving strong reasoning performance. Nature’s paper describes DeepSeek R1 as using a multistage learning framework that integrates rejection sampling, reinforcement learning, and supervised fine-tuning.
| Feature | DeepSeek R1-Zero | DeepSeek R1 |
|---|---|---|
| Main purpose | Research demonstration of reasoning through reinforcement learning | Refined reasoning model for practical use |
| Training approach | Large-scale RL without SFT as a preliminary step | Cold-start data, RL stages, SFT stages, and preference alignment |
| Strength | Strong emergent reasoning behavior | Stronger usability, readability, and alignment |
| Weaknesses | Repetition, poor readability, language mixing | Still can hallucinate, overthink, or mix languages in some settings |
| Best fit | Research into RL-driven reasoning | Practical reasoning, coding, math, and developer workflows |
| Parameter scale | 671B total, 37B activated | 671B total, 37B activated |
| Context length | 128K | 128K |
DeepSeek R1 vs DeepSeek-R1-0528
DeepSeek R1 and DeepSeek-R1-0528 belong to the same reasoning model family, but they should not be treated as identical checkpoints.
The original DeepSeek R1 release arrived on January 20, 2025. It introduced DeepSeek’s open reasoning model built for math, coding, logic, and complex problem solving. DeepSeek-R1-0528, released on May 28, 2025, was a follow-up checkpoint that improved the original R1 model rather than replacing the concept of R1 itself.
DeepSeek described DeepSeek-R1-0528 as a minor version upgrade with stronger benchmark performance, reduced hallucinations, enhanced front-end capabilities, and support for JSON output and function calling. The Hugging Face model card also states that the update improved reasoning depth and inference capability through increased computational resources and algorithmic optimization during post-training.
One of the most important differences is reasoning depth. According to the DeepSeek-R1-0528 model card, performance on AIME 2025 increased from 70.0% in the previous DeepSeek R1 version to 87.5% in DeepSeek-R1-0528. The same model card explains that the model used more reasoning tokens on AIME-style tasks, increasing from an average of about 12K tokens per question to about 23K tokens per question.
Another important distinction is structured output. The original R1 release was mainly discussed around reasoning, math, coding, and open-weight deployment. DeepSeek-R1-0528 added or improved support for JSON output and function calling, making it more useful for agent workflows, tool use, application development, and structured API responses.
However, DeepSeek-R1-0528 should not be confused with API aliases. The checkpoint name refers to the open-weight model release. API names such as deepseek-reasoner are service-level aliases that may point to different backend checkpoints over time. For technical accuracy, the article should describe DeepSeek-R1-0528 as an open-weight checkpoint released on May 28, 2025, while telling API users to verify the active model mapping in DeepSeek’s official API documentation.
| Feature | DeepSeek R1 | DeepSeek-R1-0528 |
|---|---|---|
| Release date | January 20, 2025 | May 28, 2025 |
| Role in the R1 family | Original open reasoning model release | Follow-up checkpoint / minor version upgrade |
| Main focus | Open reasoning, math, coding, reinforcement learning, distillation | Deeper reasoning, stronger benchmark results, lower hallucination rate, better structured output |
| Reasoning depth | Strong reasoning performance | Improved reasoning depth and inference capability |
| AIME 2025 | 70.0% in DeepSeek’s comparison table | 87.5% in DeepSeek’s comparison table |
| GPQA Diamond | 71.5% | 81.0% |
| LiveCodeBench | 63.5% in the R1-0528 comparison table | 73.3% |
| JSON output | Not a headline capability of the original release | Supported / improved |
| Function calling | Not a headline capability of the original release | Supported / improved |
| Hallucinations | Can still hallucinate like other LLMs | DeepSeek says hallucinations were reduced compared with the legacy R1 version |
| Deployment meaning | Open-weight R1 checkpoint and API/web access | Open-weight R1-0528 checkpoint; API aliases should be checked separately |
For an evergreen article, the best way to describe the relationship is simple: DeepSeek R1 is the original January 2025 reasoning model release, while DeepSeek-R1-0528 is a May 2025 checkpoint that improves the R1 family with deeper reasoning, stronger benchmark results, reduced hallucinations, and better support for JSON output and function calling.
How DeepSeek R1 Works
DeepSeek R1 works through a combination of reinforcement learning, chain-of-thought style reasoning, self-verification, cold-start data, and distillation.
Reinforcement Learning
Reinforcement learning is central to the DeepSeek R1 story. Instead of relying only on human-written examples of reasoning, DeepSeek used reward signals to encourage the model to produce correct answers on tasks where correctness can be verified, such as math and programming problems.
The DeepSeek R1 paper says the reasoning abilities of large language models can be incentivized through pure reinforcement learning and that the framework helped produce behaviors such as self-reflection, verification, and dynamic strategy adaptation.
Chain-of-Thought Style Reasoning
DeepSeek R1 is associated with long reasoning traces. In a user-facing sense, this means the model may produce more extended intermediate reasoning before giving a final answer.
For developers, this has two sides. It can be useful because the model may catch mistakes, test assumptions, and revise its approach. It can also increase token usage, latency, and verbosity. A good production implementation should separate the final answer from any reasoning content when appropriate.
Self-Verification and Reflection
DeepSeek R1-Zero showed behaviors such as verification and reflection during reinforcement learning. The GitHub repository describes self-verification, reflection, and long chain-of-thought generation as capabilities that emerged in DeepSeek-R1-Zero.
This is important because the model is not only generating an answer; it is often trying to evaluate whether its answer is consistent with the problem. That can be valuable for math, code, logic puzzles, and structured analysis.
Cold-Start Data
R1-Zero’s raw reasoning behavior was powerful but not always user-friendly. DeepSeek R1 added cold-start data before reinforcement learning to improve readability and reduce issues such as repetition and language mixing.
Cold-start data helps provide a more stable starting point for the model’s reasoning behavior. In practice, this makes DeepSeek R1 more suitable for users who want useful answers, not just research demonstrations.
Distillation
Distillation transfers useful behavior from a larger model to smaller models. DeepSeek used reasoning data generated by DeepSeek R1 to fine-tune dense models based on Qwen and Llama.
This matters because most developers cannot run a 671B-parameter model easily. A distilled 7B, 14B, or 32B model can be much more practical for experimentation, local inference, and constrained deployments.
Mixture-of-Experts Architecture
DeepSeek R1 uses a Mixture-of-Experts architecture inherited from the DeepSeek-V3-Base lineage. The model has 671B total parameters but activates 37B parameters per token. This allows a very large model capacity while keeping the active computation per token lower than a dense model of the same total size.
DeepSeek R1 Architecture and Specifications
| Model | Total Parameters | Activated Parameters | Context Length | Base Relationship | Intended Use |
|---|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128K | Trained based on DeepSeek-V3-Base | Research into RL-driven reasoning |
| DeepSeek-R1 | 671B | 37B | 128K | Trained based on DeepSeek-V3-Base | Practical reasoning, coding, math, and analysis |
| DeepSeek-R1-Distill models | 1.5B to 70B | Dense model sizes vary | Depends on serving setup and variant | Fine-tuned from Qwen2.5 and Llama 3 series using R1-generated samples | Local experiments, smaller deployments, developer workflows |
The main R1 and R1-Zero models are both listed at 671B total parameters, 37B activated parameters, and 128K context length. The distilled models are separate dense checkpoints based on open Qwen and Llama models.
DeepSeek R1 Distilled Models
DeepSeek R1 Distill models are smaller models trained using samples generated by DeepSeek R1. They are designed to bring some of the larger model’s reasoning patterns into more practical model sizes.
The official repository lists six distilled checkpoints:
| Distilled Model | Base Model | Approximate Target User | Local Deployment Suitability |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | Beginners, lightweight testing, education demos | Very suitable for low-resource experiments |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | Developers testing local reasoning | Suitable for consumer and small GPU setups, depending on quantization |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | Llama ecosystem users | Suitable for local experimentation |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | More serious local reasoning and coding tests | Moderate local requirements |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | Advanced developers, research, stronger local reasoning | Higher hardware requirements |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | Teams with stronger inference infrastructure | Demands significant compute |
The distilled Qwen models are derived from Qwen2.5 models, while the Llama variants are derived from Llama 3.1 and Llama 3.3 models. DeepSeek’s license section also notes that these distilled models retain upstream license considerations from their original base models.
DeepSeek R1 Benchmarks
DeepSeek R1 benchmarks should be read carefully. Benchmarks are useful for comparison, but they do not guarantee performance on every real-world task. Model behavior depends on prompt quality, decoding settings, inference setup, domain, evaluation method, and data contamination controls.
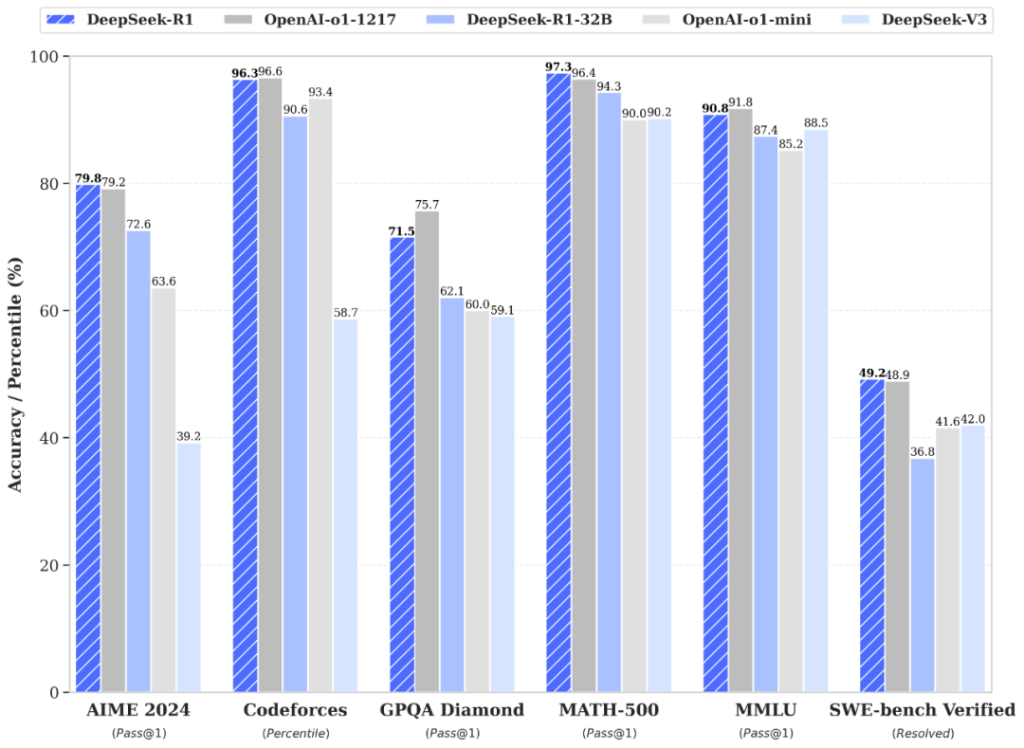
DeepSeek’s published evaluation table uses a maximum generation length of 32,768 tokens; for sampling benchmarks, it reports temperature 0.6, top-p 0.95, and 64 responses per query to estimate pass@1.
| Benchmark | Metric | DeepSeek R1 Result |
|---|---|---|
| MMLU | Pass@1 | 90.8 |
| MMLU-Redux | EM | 92.9 |
| MMLU-Pro | EM | 84.0 |
| GPQA Diamond | Pass@1 | 71.5 |
| LiveCodeBench | Pass@1-COT | 65.9 |
| Codeforces | Percentile | 96.3 |
| Codeforces | Rating | 2029 |
| SWE Verified | Resolved | 49.2 |
| AIME 2024 | Pass@1 | 79.8 |
| MATH-500 | Pass@1 | 97.3 |
| CNMO 2024 | Pass@1 | 78.8 |
DeepSeek’s evaluation table also compares R1 with Claude-3.5-Sonnet-1022, GPT-4o-0513, DeepSeek V3, OpenAI o1-mini, and OpenAI o1-1217. In that table, DeepSeek R1 performs strongly on math and coding benchmarks, including AIME 2024, MATH-500, LiveCodeBench, and Codeforces.
DeepSeek R1 vs DeepSeek-R1-0528 Benchmarks
| Benchmark | DeepSeek R1 | DeepSeek-R1-0528 |
|---|---|---|
| AIME 2025 | 70.0% | 87.5% |
| AIME 2024 | 79.8% | 91.4% |
| GPQA Diamond | 71.5% | 81.0% |
| LiveCodeBench | 63.5% | 73.3% |
| SWE Verified | 49.2% | 57.6% |
| Codeforces Rating | 1530 | 1930 |
| MMLU-Redux | 92.9% | 93.4% |
| MMLU-Pro | 84.0% | 85.0% |
| CNMO 2024 | 78.8% | 86.9% |
DeepSeek R1 Distill Benchmark Highlights
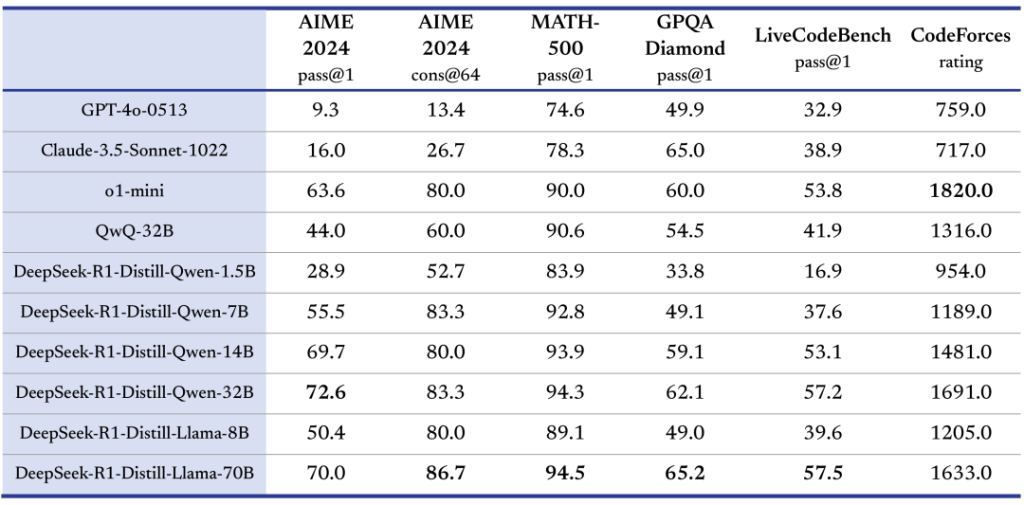
| Model | AIME 2024 Pass@1 | MATH-500 Pass@1 | GPQA Diamond Pass@1 | LiveCodeBench Pass@1 | Codeforces Rating |
|---|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 94.5 | 65.2 | 57.5 | 1633 |
These results show why DeepSeek R1 Distill models became important for local AI workflows: the smaller checkpoints preserve useful reasoning behavior while being much easier to run than the full 671B model.
DeepSeek R1 vs OpenAI o1, GPT-4o, and Claude
The phrase “DeepSeek R1 vs OpenAI o1” is popular because both models are associated with reasoning. However, the comparison should be framed carefully.
DeepSeek R1’s main advantage is openness. Developers can download weights, run variants locally, inspect outputs, and use distilled models. OpenAI o1, GPT-4o, and Claude models are generally consumed through hosted products or APIs. Closed models may still be preferable for polished user experiences, enterprise workflows, multimodal product integrations, safety systems, or vendor-supported deployments.
| Dimension | DeepSeek R1 | OpenAI o1 | GPT-4o | Claude |
|---|---|---|---|---|
| Reasoning | Strong on math, code, and structured problem solving | Strong reasoning model | More general multimodal assistant style | Strong writing, analysis, and coding depending on model/version |
| Openness | Open weights for R1 series | Closed | Closed | Closed |
| Local deployment | Possible with weights and serving stacks; full model is hardware-heavy | Not generally available as open weights | Not generally available as open weights | Not generally available as open weights |
| Distilled variants | Yes, Qwen and Llama-based R1 Distill models | No direct equivalent from OpenAI o1 | No direct equivalent | No direct equivalent |
| Cost control | Strong potential when self-hosted; hosted pricing should be verified from provider docs | API/product pricing | API/product pricing | API/product pricing |
| Privacy | Can be self-hosted for more control | Hosted model workflow | Hosted model workflow | Hosted model workflow |
| Creative writing | Capable, but may be verbose or reasoning-heavy | Can be strong, depending on product context | Often strong for general assistant tasks | Often strong for polished prose and long-form writing |
| Best fit | Open reasoning, local AI, math, coding, research, distillation | Closed-model reasoning workflows | Multimodal and broad assistant workflows | Writing, analysis, coding, and enterprise assistant workflows |
DeepSeek’s own evaluation table reports DeepSeek R1 at 79.8 on AIME 2024, 97.3 on MATH-500, 71.5 on GPQA Diamond, 65.9 on LiveCodeBench, and 2029 Codeforces rating, alongside comparison rows for OpenAI o1-1217, o1-mini, GPT-4o-0513, and Claude-3.5-Sonnet-1022.
How to Use DeepSeek R1
There are four main ways to use DeepSeek R1: web interface, API, model weights, and local deployment.
Web Interface and DeepThink
The DeepSeek R1 release page announced website access and described DeepThink as the web mode for trying R1-style reasoning.
This is the easiest option for non-developers. It requires no local setup and is useful for testing the model’s reasoning behavior before deciding whether to use an API or local deployment.
DeepSeek R1 API
DeepSeek’s original release page described API access by setting the model to deepseek-reasoner. It also pointed users to the official API guide.
DeepSeek’s API documentation describes an OpenAI/Anthropic-compatible API format, with examples using the OpenAI SDK, a DeepSeek base URL, API keys, and reasoning-related parameters. Because API model names and product routing can change, production users should verify model identifiers in the official DeepSeek API documentation before deployment.
Hugging Face Model Weights
The official Hugging Face model card hosts DeepSeek-R1 and includes model details, variants, evaluation summaries, local usage notes, and links to related resources. It also states that DeepSeek-R1-Zero, DeepSeek-R1, and six distilled dense models were open-sourced based on Llama and Qwen.
Local Deployment
Local deployment is one of DeepSeek R1’s biggest advantages. Developers can experiment with full or distilled models through tools such as Ollama, vLLM, SGLang, and other compatible inference stacks.
For most individuals, distilled models are the practical starting point. The full 671B model requires far more serious inference infrastructure.
How to Run DeepSeek R1 Locally
The right local setup depends on the variant you choose. A 1.5B or 7B distilled model is very different from the full 671B model in hardware requirements.
DeepSeek R1 Ollama Setup
Ollama lists DeepSeek R1 tags across multiple sizes, including 1.5B, 7B, 8B, 14B, 32B, 70B, and 671B. The Ollama tag page also shows text input and a 128K context window for listed tags.
Example command:
ollama run deepseek-r1:7bFor a smaller experiment:
ollama run deepseek-r1:1.5bFor a larger distilled model:
ollama run deepseek-r1:32bHardware requirements depend on model size, quantization, context length, runtime, and available memory. Do not assume that every listed model will run well on every consumer machine.
Run DeepSeek R1 Distill with vLLM
DeepSeek’s GitHub repository gives this example for serving a distilled model with vLLM:
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B \
--tensor-parallel-size 2 \
--max-model-len 32768 \
--enforce-eagerThe repository states that DeepSeek-R1-Distill models can be used in the same manner as Qwen or Llama models.
vLLM documentation also supports reasoning outputs for models such as DeepSeek R1, returning a separate reasoning field in supported setups.
Run DeepSeek R1 with SGLang
DeepSeek’s repository also provides an SGLang launch example for a distilled checkpoint:
python3 -m sglang.launch_server \
--model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B \
--trust-remote-code \
--tp 2SGLang documentation includes DeepSeek R1 support, reasoning parsing, and launch examples for larger DeepSeek models.
For advanced deployments, SGLang’s reasoning parser supports DeepSeek-R1 family variants using <think> and </think> reasoning delimiters.
Prompting Tips for DeepSeek R1
DeepSeek R1 performs best when the task is clear, structured, and specific. The official repository gives several usage recommendations, including temperature settings, prompt structure, and evaluation advice.
1. Use Clear User Prompts
Do not rely on vague instructions. Instead of:
Solve this.Use:
Solve the following algebra problem step by step. Show the final answer clearly at the end.2. Use Temperature Around 0.6
DeepSeek recommends temperature between 0.5 and 0.7, with 0.6 recommended, to reduce endless repetition or incoherent output.
3. Put Instructions in the User Prompt
The official repository recommends avoiding a system prompt and placing instructions inside the user prompt.
4. Ask for Final Answer Formatting
For math, DeepSeek recommends a directive such as asking the model to reason step by step and place the final answer in a boxed format.
Example:
Please solve the problem step by step and put the final answer in \boxed{}.5. Run Multiple Evaluations
For benchmarking or production testing, do not rely on one answer. DeepSeek recommends conducting multiple tests and averaging results when evaluating performance.
6. Control Verbosity
DeepSeek R1 can be verbose. For production apps, specify the desired output:
Give a concise final answer first, then provide a short explanation in no more than five bullet points.Best Use Cases for DeepSeek R1
DeepSeek R1 is most useful when the task benefits from deliberate reasoning.
Math Problem Solving
DeepSeek R1 is a strong fit for algebra, calculus, olympiad-style questions, proofs, and structured quantitative reasoning.
Competitive Programming and Coding
The model performs well on coding and algorithmic reasoning benchmarks. It can help with problem decomposition, pseudocode, bug analysis, and test-case reasoning.
Code Review
DeepSeek R1 can inspect logic, identify edge cases, explain potential bugs, and suggest refactors. It should not replace human review for security-critical code.
Research Assistance
The model can help summarize technical material, compare concepts, generate hypotheses, and outline experiments. It should be paired with source verification.
Data Analysis Reasoning
DeepSeek R1 can help plan analyses, explain statistical assumptions, reason through spreadsheet logic, or translate business questions into analytical steps.
Education and Tutoring
The model is useful for step-by-step explanation, practice problems, coding exercises, and guided reasoning.
Planning and Multi-Step Problem Solving
DeepSeek R1 can break down complex tasks into sequences, compare trade-offs, and identify dependencies.
Local and Private AI Workflows
Open weights and distilled variants make DeepSeek R1 attractive for local AI experiments, internal tools, and controlled deployments.
Limitations and Risks
DeepSeek R1 is powerful, but it is not perfect.
Hallucinations
DeepSeek R1 can generate incorrect facts, flawed citations, or plausible but wrong explanations. Use retrieval, verification, and human review for factual or high-stakes tasks.
Verbose Reasoning
Reasoning models often produce long responses. This can increase latency and cost in hosted environments and can make outputs harder to use without formatting controls.
Language Mixing
Nature’s DeepSeek R1 paper notes that R1 can show language-mixing issues, especially outside Chinese and English.
Repetition
DeepSeek R1-Zero had notable repetition problems. DeepSeek R1 improves usability, but repetition can still appear in some inference settings or poor sampling configurations.
Hosted API Privacy Considerations
When using hosted APIs, prompts and outputs are processed by the provider. For sensitive data, review provider terms, retention policies, and compliance requirements.
Hardware Requirements
The full DeepSeek R1 671B model is not a casual local deployment. Most users should begin with distilled variants. Hardware needs depend on model size, quantization, runtime, context length, and throughput expectations.
Benchmark vs Real-World Gap
Benchmarks are helpful, but they do not guarantee performance in every product workflow. Test DeepSeek R1 on your actual prompts, data, latency targets, and quality standards.
Tool Use and Structured Output
The Nature paper describes structure output, tool use, token efficiency, language mixing, prompt sensitivity, and software-engineering tasks as limitation areas for DeepSeek R1.
Should You Use DeepSeek R1?
Use DeepSeek R1 if you need open reasoning, local deployment options, math and coding strength, model-weight access, distillation experiments, or more control over inference infrastructure.
Consider alternatives if your priority is a polished general-purpose assistant, strict vendor-managed enterprise support, advanced multimodal product workflows, or highly refined creative writing. DeepSeek R1 can write and summarize, but its strongest value is reasoning-heavy work where openness and technical control matter.
A practical approach is to start with a distilled model for local testing, compare it against your preferred hosted models on real tasks, and then decide whether the full model, a distilled variant, or a closed-model API is the best fit.
FAQ
What is DeepSeek R1?
DeepSeek R1 is an open reasoning model from DeepSeek designed for complex math, coding, logic, and multi-step problem solving. It was released on January 20, 2025, with open model weights and a technical report.
Is DeepSeek R1 open source?
DeepSeek’s release described DeepSeek R1 as fully open-source, and the GitHub repository states that the code repository and model weights are licensed under the MIT License. The repository also says the R1 series supports commercial use, modifications, derivative works, and distillation.
Can DeepSeek R1 run locally?
Yes. DeepSeek R1 can be run locally through compatible inference tools, but the full 671B model requires substantial infrastructure. Most users should start with DeepSeek R1 Distill models through Ollama, vLLM, SGLang, or similar tools.
What is DeepSeek R1 Distill?
DeepSeek R1 Distill refers to smaller dense models fine-tuned using samples generated by DeepSeek R1. DeepSeek released distilled models based on Qwen2.5 and Llama 3 series checkpoints in sizes from 1.5B to 70B.
What is the difference between DeepSeek R1 and R1-Zero?
DeepSeek R1-Zero was trained through large-scale reinforcement learning without supervised fine-tuning as a preliminary step. DeepSeek R1 added cold-start data and a more refined training pipeline to improve usability, readability, and alignment while preserving strong reasoning performance.
What is DeepSeek-R1-0528?
DeepSeek-R1-0528 is a May 28, 2025 checkpoint update to the DeepSeek R1 family. It improved reasoning depth, benchmark performance, hallucination behavior, and support for JSON output and function calling.
Is DeepSeek R1 better than OpenAI o1?
Not universally. DeepSeek R1 is especially attractive because it is open and performs strongly on reasoning, math, and coding benchmarks. OpenAI o1 may still be preferred in some hosted workflows, product integrations, or closed-model environments. The better choice depends on the use case.
What hardware is needed for DeepSeek R1?
Hardware depends on the model size and quantization. The full 671B model requires serious infrastructure. Distilled models such as 1.5B, 7B, 8B, 14B, and 32B are more practical for local experimentation, depending on available CPU/GPU memory.
Can DeepSeek R1 be used commercially?
The DeepSeek-R1 repository states that the code and model weights are MIT licensed and that the DeepSeek-R1 series supports commercial use. For distilled models, users should also review the upstream Qwen or Llama license terms noted in the repository.
Does DeepSeek R1 show its reasoning?
DeepSeek R1-style models can produce reasoning content. vLLM and SGLang both document support for parsing or separating reasoning outputs for DeepSeek R1-style models.
Is DeepSeek R1 good for coding?
Yes, DeepSeek R1 performs strongly on coding-oriented evaluations such as LiveCodeBench and Codeforces in DeepSeek’s published benchmark table. Real-world coding performance should still be tested on your own tasks.
What are DeepSeek R1’s limitations?
DeepSeek R1 can hallucinate, overthink, produce verbose outputs, mix languages in some scenarios, struggle with structured output or tool-use workflows, and require significant compute for larger variants.
Conclusion
DeepSeek R1 is an important open reasoning model because it combines strong math, coding, and logic performance with open model weights, distilled variants, and practical deployment options. It is especially useful for developers and researchers who want more control than a closed hosted model can provide.
For most users, the best starting point is not the full 671B model. Start with a DeepSeek R1 Distill variant, test it on real prompts, compare it with hosted alternatives, and choose the setup that best balances quality, speed, cost, privacy, and operational complexity.