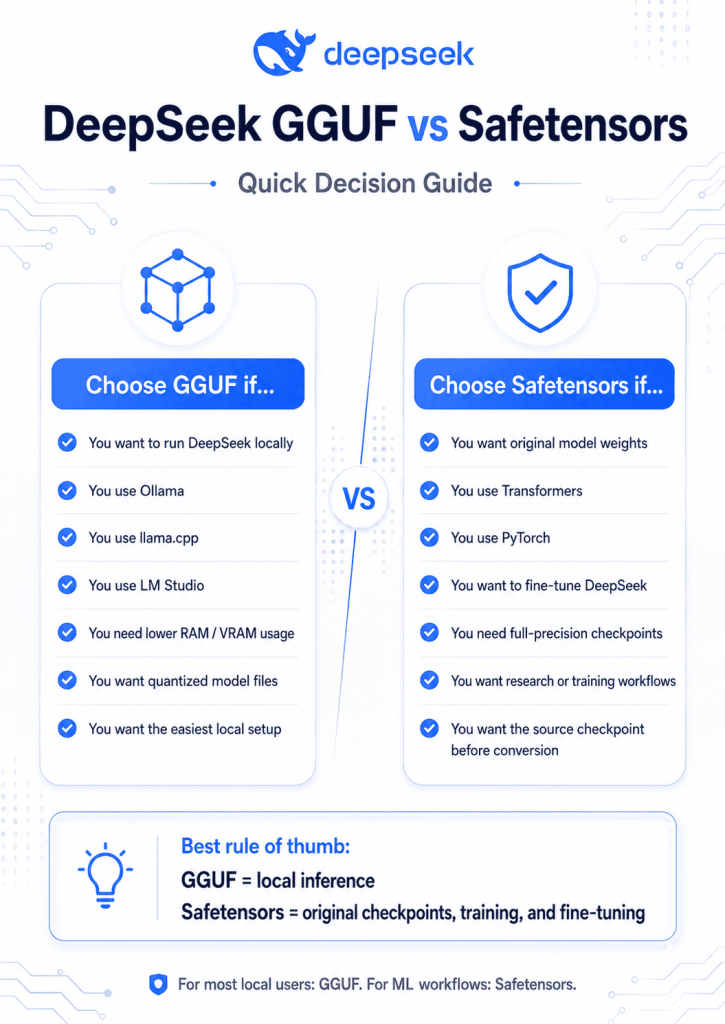
If you want to run DeepSeek locally in Ollama, llama.cpp, LM Studio, GPT4All, or a similar desktop app, choose GGUF. If you want the original model checkpoint for PyTorch, Transformers, research, fine-tuning, or full-precision workflows, choose Safetensors. The real answer to DeepSeek GGUF vs Safetensors is not “one is always better.” They are built for different parts of the LLM workflow.
GGUF is popular for local inference because it is a single-file model format with metadata and tensors, supports many quantized data types, and is used across tools such as llama.cpp, Ollama, LM Studio, and GPT4All. Safetensors is a safe and fast tensor storage format designed to avoid pickle-related code execution risks and is widely used for Hugging Face model checkpoints.
This guide focuses mainly on DeepSeek-R1, DeepSeek-R1-0528, and their distilled or quantized variants. As of 2026, DeepSeek has also released newer model families such as DeepSeek-V4 Preview, but the GGUF vs Safetensors question remains especially common around R1/R1-0528 local inference and Hugging Face downloads.
Quick Verdict: GGUF or Safetensors for DeepSeek?
| Use Case | Choose GGUF | Choose Safetensors | Why |
|---|---|---|---|
| Running DeepSeek in Ollama | Yes | Sometimes | GGUF is usually the simplest local route; Ollama can also import Safetensors for supported architectures. |
| Running DeepSeek in llama.cpp | Yes | No | llama.cpp uses GGUF for local inference. |
| Running DeepSeek in LM Studio | Yes | No | LM Studio commonly uses GGUF models from Hugging Face. |
| Fine-tuning DeepSeek | Usually no | Yes | Safetensors is better suited to PyTorch, Transformers, and training checkpoints. |
| Using Transformers/PyTorch | Sometimes | Yes | Transformers can load GGUF in some workflows, but Safetensors remains the standard checkpoint format. |
| Lowest RAM/VRAM usage | Yes | No | Quantized GGUF files can greatly reduce memory requirements. |
| Best possible weight fidelity | Maybe, if F16/BF16 | Yes | Original Safetensors weights preserve the checkpoint as distributed. |
| Production serving | Depends | Depends | vLLM, SGLang, TGI, llama.cpp, and Ollama have different format support. |
| Converting models | Target format | Source format | Many users convert Safetensors checkpoints into GGUF for local inference. |
| Archiving original weights | No | Yes | A quantized GGUF is not a lossless backup of the original model. |
Ollama’s current documentation is more nuanced than many older tutorials suggest: it documents importing both Safetensors models for supported architectures and GGUF files through a Modelfile. It also documents quantizing FP16/FP32 models with ollama create --quantize.
What Is GGUF?
GGUF is a binary model file format designed for inference with GGML-based executors such as llama.cpp. The ggml specification describes GGUF as a format for storing models for inference, designed for fast loading and saving, ease of reading, single-file deployment, extensibility, mmap compatibility, and including the information needed to load a model.
In simpler terms, GGUF is the format you usually download when you want to run a local LLM without setting up a full PyTorch environment. A DeepSeek GGUF file may contain the model tensors, metadata, tokenizer-related information, and quantized weights in one package, depending on how the publisher created it.
Hugging Face describes GGUF as a single-file format containing model metadata and tensors, and its Hub GGUF viewer can inspect metadata and tensor information such as tensor name, shape, and precision. Hugging Face also lists open-source tools such as llama.cpp, LM Studio, GPT4All, and Ollama as GGUF-compatible tools.
GGUF matters for DeepSeek because full DeepSeek reasoning models are large. The original DeepSeek-R1 model card lists DeepSeek-R1 and DeepSeek-R1-Zero as 671B total-parameter models with 37B activated parameters and a 128K context length. For most people, that means a distilled model or quantized GGUF variant is far more practical than downloading full original weights and trying to run them directly.
Common GGUF quantization names include:
F16orBF16— high precision, large file size.Q8_0— 8-bit quantization, usually strong quality but larger than 4-bit options.Q6_K— a higher-quality quantized option.Q5_K_M— a common balance between quality and size.Q4_K_M— one of the most popular general-purpose local inference choices.Q3,Q2, andIQvariants — smaller, more aggressive quants that may fit limited hardware.
These labels are not always perfectly uniform across publishers. For example, some DeepSeek GGUF repositories use publisher-specific labels such as UD-Q4_K_XL or dynamic quantization names. Always read the model card before assuming what a tag means.
What Is Safetensors?
Safetensors is a file format for storing tensors safely and quickly. Hugging Face describes it as a simple format for storing tensors safely, as opposed to pickle, while still being fast and supporting zero-copy behavior.
The main reason Safetensors became popular is security. Traditional PyTorch .bin files can rely on pickle, and pickle-based formats can execute code during deserialization. Safetensors avoids that class of risk by storing tensor data in a simpler structure. PyTorch’s Safetensors project page describes it as a secure and fast format that prevents arbitrary code execution during deserialization by only allowing numerical tensor data.
Safetensors is also practical for large model hosting. Hugging Face’s metadata parsing documentation explains that Safetensors metadata can be fetched and parsed efficiently, including tensor names, types, shapes, and parameter counts, without downloading the entire file.
For DeepSeek, Safetensors is usually what you want when you need:
- Original model weights.
- PyTorch or Transformers workflows.
- Research reproducibility.
- Fine-tuning or continued training.
- Full-precision or near-full-precision checkpoints.
- A source checkpoint before converting to GGUF.
Safetensors is not an inference engine. It stores tensors. The runtime still matters: Transformers, vLLM, SGLang, TGI, Ollama, or another engine must know how to interpret the model architecture, tokenizer, config, chat template, and generation settings.
DeepSeek GGUF vs Safetensors: Full Comparison Table
| Category | GGUF | Safetensors |
|---|---|---|
| Primary purpose | Local inference with GGML-based tools | Safe storage of model tensors/checkpoints |
| Best for | Ollama, llama.cpp, LM Studio, desktop local LLMs | Transformers, PyTorch, fine-tuning, research |
| Local inference | Excellent for supported tools | Depends on runtime and architecture support |
| Training/fine-tuning | Not the usual choice | Usually the better choice |
| Quantization | Built around many quantized GGUF variants | Usually stores original or training-ready tensors |
| File size | Often smaller when quantized | Often larger, especially BF16/FP16 checkpoints |
| RAM/VRAM usage | Can be much lower with Q4/Q5/Q6/IQ quants | Higher unless runtime applies separate quantization |
| Metadata | Designed to include model metadata and tensors | Stores named tensors and optional metadata; config/tokenizer usually remain separate |
| Tool compatibility | llama.cpp, Ollama, LM Studio, GPT4All, some vLLM workflows | Transformers, PyTorch, TGI, many training stacks |
| Security | Binary model format; inspect publisher trust | Designed to avoid pickle-style code execution risks |
| Conversion | Common target after converting from Hugging Face checkpoints | Common source format before GGUF conversion |
| Quality trade-off | Quantized GGUF may lose some accuracy | Original weights preserve checkpoint fidelity |
| Ease for beginners | Easier for local chat apps | Easier for ML engineers using Hugging Face |
| Best DeepSeek user type | Local LLM users and hobbyists | ML engineers, researchers, fine-tuners |
A useful mental model: Safetensors is often the checkpoint format; GGUF is often the local inference format. They overlap in some workflows, but they are not direct replacements for every task.
Why DeepSeek Users See Both Formats on Hugging Face
DeepSeek users often see Safetensors and GGUF because they are looking at different stages of the model lifecycle.
Original model repositories on Hugging Face commonly use Safetensors because it is the preferred format for safely sharing model weights across the ML ecosystem. Hugging Face and the PyTorch Foundation both describe Safetensors as a secure, fast format for model weights, and Hugging Face notes that Safetensors has become widely adopted across the Hub.
GGUF repositories, on the other hand, are often created for local inference. The same DeepSeek model may appear in many GGUF files because each file may use a different quantization level: Q8_0, Q6_K, Q5_K_M, Q4_K_M, IQ2, and so on.
This is especially important for DeepSeek-R1 and DeepSeek-R1-0528. DeepSeek-R1’s official model card lists the full model at 671B total parameters, 37B activated parameters, and 128K context length. The DeepSeek-R1-0528 model card describes it as a version upgrade with improved reasoning depth, reduced hallucination rate, enhanced function calling, and better “vibe coding” experience.
For local users, the full checkpoint is usually unrealistic. Unsloth’s local R1-0528 guide states that the full 671B model requires 715GB of disk space, while a dynamic 1.66-bit quantized version uses 162GB. That is still large, but it shows why quantized GGUF variants exist.
Which Format Should You Download for DeepSeek-R1 or DeepSeek-R1-0528?
Choose based on what you are actually trying to do.
Choose GGUF if you want local inference
Use GGUF for:
- Ollama DeepSeek GGUF runs.
- llama.cpp DeepSeek inference.
- LM Studio chat.
- GPT4All-style desktop use.
- CPU-only or low-VRAM machines.
- Smaller quantized files.
- Quick local testing.
Hugging Face’s Ollama integration documentation says users can run GGUF quants from the Hub directly with ollama run hf.co/{username}/{repository}, and it notes that Q4_K_M is used by default when present in a model repository.
Example:
ollama run hf.co/unsloth/DeepSeek-R1-0528-GGUF:UD-Q4_K_XLUnsloth’s DeepSeek-R1-0528 GGUF page provides this kind of Ollama command, along with llama.cpp commands for llama-server and llama-cli.
Choose Safetensors if you want model weights
Use Safetensors for:
- Transformers.
- PyTorch.
- Fine-tuning.
- Research.
- Full-precision or original checkpoints.
- Converting the model yourself.
- Archiving original weights.
For DeepSeek-R1 distilled models, the official model card says the distill models can be used in the same manner as Qwen or Llama models and gives vLLM and SGLang examples. That kind of workflow is much closer to Safetensors than to beginner-friendly GGUF chat apps.
Choose distilled models for smaller hardware
Most local users should not start with the full DeepSeek-R1 or R1-0528 model. A distilled DeepSeek model, such as an 8B, 14B, 32B, or 70B variant, is usually more realistic.
If you have a normal laptop, start with a smaller distilled GGUF model. If you have a high-end workstation, test Q4_K_M, Q5_K_M, Q6_K, or Q8_0. If you need maximum fidelity and have the hardware, use Safetensors or a high-bit GGUF such as F16/BF16/Q8_0 when available.
Understanding DeepSeek GGUF Quantization Names
GGUF quantization reduces model weight precision so the model can fit into less RAM, VRAM, or unified memory. The trade-off is that aggressive quantization can reduce accuracy or reasoning quality.
The llama.cpp quantization documentation explains that quantization reduces precision, such as moving from 32-bit floats to 4-bit integers, which shrinks model size and can speed up inference, but may introduce accuracy loss.
| Hardware / Goal | Suggested Quant | Notes |
|---|---|---|
| Best quality, large memory | F16, BF16, Q8_0 | Largest files, strongest fidelity. |
| High quality, less memory | Q6_K | Good option when you have enough RAM/VRAM. |
| Balanced local use | Q5_K_M | Often a strong quality/size compromise. |
| Most beginner local setups | Q4_K_M | Common default for Ollama/Hugging Face GGUF runs. |
| Very limited memory | Q3, Q2, IQ variants | Fits smaller hardware but may harm reasoning. |
| Large DeepSeek-R1 full model attempts | Dynamic low-bit quants | Only for users who understand the memory and quality trade-offs. |
What the labels generally suggest:
F16/BF16: half-precision formats, not small quants.Q8_0: 8-bit quantization.Q6_K: 6-bit K-quant family.Q5_K_M: 5-bit K-quant, usually “medium” variant.Q4_K_M: 4-bit K-quant, widely used for general local inference.Q3/Q2: smaller but more aggressive.IQ: importance-aware or newer low-bit quant families, depending on publisher/tooling.S,M,XL,UD,TQ: often publisher- or quant-family-specific labels, so check the model card.
Avoid choosing the smallest file just because it downloads faster. DeepSeek reasoning models can be sensitive to aggressive quantization, especially on math, code, and long reasoning prompts.
Does GGUF Reduce DeepSeek Quality?
GGUF itself does not automatically mean “low quality.” A high-precision GGUF can preserve much more of the original model than a very low-bit quant. The quality loss usually comes from quantization, not from the file extension.
A Q8_0 or Q6_K DeepSeek GGUF may perform very well but require more memory. A Q4_K_M file is often a good practical compromise. A Q2 or very low-bit IQ file may fit small machines but can lose reasoning reliability.
Ollama’s documentation explains the same trade-off clearly: quantizing a model can make it faster and reduce memory consumption, but with reduced accuracy.
For DeepSeek-R1 and DeepSeek-R1-0528, test your own prompts. Do not rely only on one benchmark or one Reddit comment. Try your model on:
- Math reasoning.
- Coding tasks.
- Long prompts.
- Tool-use prompts.
- Your real production prompts.
- Multi-turn conversations.
A practical testing order is:
- Try
Q4_K_M. - If quality is weak and you have memory, try
Q5_K_M. - If you still need stronger reasoning, try
Q6_KorQ8_0. - If you cannot fit the model, move to a smaller distilled DeepSeek model instead of over-compressing the full model.
How to Convert DeepSeek Safetensors to GGUF
Converting DeepSeek Safetensors to GGUF is common when you want to use a Hugging Face checkpoint in llama.cpp or another GGUF-based tool.
The high-level workflow is:
- Confirm that llama.cpp supports the model architecture.
- Download the original DeepSeek or distilled DeepSeek model from Hugging Face.
- Install or build llama.cpp.
- Convert the Hugging Face model directory to GGUF.
- Quantize the GGUF if needed.
- Test the model.
- Verify tokenizer, chat template, context length, and generation parameters.
Hugging Face’s llama.cpp integration documentation states that llama.cpp uses GGUF and that Transformers models can be converted to GGUF with convert_hf_to_gguf.py. The llama.cpp quantization documentation gives an example flow where a model directory containing Safetensors and tokenizer files is converted with convert_hf_to_gguf.py, then quantized with llama-quantize.
Example workflow:
# 1. Clone llama.cpp
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
# 2. Install Python requirements
python3 -m pip install -r requirements.txt
# 3. Convert a Hugging Face model directory to GGUF
python3 convert_hf_to_gguf.py /path/to/deepseek-model \
--outfile deepseek-f16.gguf
# 4. Quantize to Q4_K_M
./build/bin/llama-quantize deepseek-f16.gguf deepseek-Q4_K_M.gguf Q4_K_M
# 5. Test with llama.cpp
./build/bin/llama-cli -m deepseek-Q4_K_M.gguf -p "Explain GGUF vs Safetensors."Script names and build paths can change. Always check the current llama.cpp documentation before building an automated conversion workflow.
Also, conversion is not guaranteed for every DeepSeek architecture. If the converter says the architecture is unsupported, you need either a newer llama.cpp build, a supported distilled model, or an existing GGUF quant from a trusted publisher.
Can You Convert DeepSeek GGUF Back to Safetensors?
Sometimes tools can load a GGUF checkpoint and expose weights in a PyTorch-compatible form. Hugging Face Transformers documents GGUF loading and explains that a GGUF checkpoint is dequantized to FP32 when loaded for further training or fine-tuning.
But this does not mean a quantized GGUF is a lossless backup of the original Safetensors model.
If you have a Q4_K_M, Q3, Q2, or IQ GGUF file, the original BF16/FP16 weights have already been compressed. Dequantizing can create floating-point tensors again, but it cannot recreate the exact original weights. The information lost during quantization is gone.
Use this rule:
- Need the original model? Download Safetensors.
- Need local inference? Download GGUF.
- Need to fine-tune seriously? Start from Safetensors or a training-supported quantized method.
- Need to preserve weights long-term? Archive the original Safetensors checkpoint, tokenizer, config, generation config, license, and model card.
Common Problems and Fixes
| Problem | Likely Cause | Fix |
|---|---|---|
“I downloaded DeepSeek but there is no .gguf file.” | You downloaded the original Safetensors checkpoint. | Look for a GGUF quantization repo or convert it yourself. |
| “Ollama cannot load my DeepSeek Safetensors.” | Unsupported architecture, missing config, or import limitation. | Use a GGUF file, or confirm your model architecture is supported by Ollama. |
| “The model outputs gibberish.” | Wrong tokenizer, prompt template, quantization issue, or bad conversion. | Use the model card’s template and recommended settings. |
| “Tensor size mismatch.” | Wrong architecture/config or incompatible conversion. | Re-download the full model directory and use the latest converter. |
| “Wrong tokenizer or chat template.” | GGUF metadata or app template does not match DeepSeek. | Copy the official template/settings from the model card. |
| “The GGUF file is split into multiple parts.” | Large GGUF models are often sharded. | Use tool-specific split/merge instructions. vLLM currently documents single-file GGUF support and recommends merging multi-file GGUFs. |
| “My RAM/VRAM is not enough.” | Quant is too large or context length is too high. | Use a smaller quant, smaller distill, lower context, or more offloading. |
| “vLLM/Transformers does not load my GGUF.” | GGUF support differs by tool and may be experimental. | Use Safetensors for vLLM/Transformers when possible, or check current GGUF support. |
| “Which file should I pick from a long GGUF list?” | Many quantization options exist. | Start with Q4_K_M; move up to Q5_K_M, Q6_K, or Q8_0 if you need quality and have memory. |
DeepSeek-R1 also has usage recommendations that matter regardless of format. The official model card recommends temperature around 0.5–0.7, with 0.6 recommended, and top-p 0.95 for expected performance.
Final Recommendation: DeepSeek GGUF vs Safetensors
The best format depends on your job.
Choose GGUF if you want to run a local DeepSeek model in Ollama, llama.cpp, LM Studio, GPT4All, or another local inference tool. GGUF is usually the practical choice for local DeepSeek inference because it supports quantized files, can reduce memory requirements, and is widely used by consumer-friendly LLM apps.
Choose Safetensors if you want original weights, training, fine-tuning, PyTorch, Transformers, reproducible research, or checkpoint archiving. Safetensors is not an inference engine, but it is the better format for safely storing and working with model tensors in the Hugging Face ecosystem.
For most beginners searching DeepSeek GGUF vs Safetensors, the answer is simple:
Download GGUF for local chat. Download Safetensors for ML work.
For most engineers, the answer is more precise:
Use Safetensors as the source checkpoint, convert to GGUF when you need llama.cpp/Ollama-style inference, and never treat a low-bit GGUF as a lossless replacement for the original model.
FAQ
Is GGUF better than Safetensors for DeepSeek?
GGUF is better for running DeepSeek locally in tools like Ollama, llama.cpp, LM Studio, and GPT4All. Safetensors is better for original checkpoints, PyTorch, Transformers, fine-tuning, and research. They solve different problems.
Should I use GGUF or Safetensors for Ollama?
Use GGUF if you want the easiest Ollama setup. Ollama also documents Safetensors import for supported architectures, but GGUF is still usually simpler for local DeepSeek inference.
Can I fine-tune a DeepSeek GGUF model?
GGUF is not the usual starting point for fine-tuning. Use Safetensors or another training-supported checkpoint format. Transformers can load some GGUF models by dequantizing them, but that does not make quantized GGUF the best fine-tuning source.
Does GGUF make DeepSeek faster?
Not automatically. Speed depends on quantization, hardware, CPU/GPU offloading, memory bandwidth, runtime, batch size, and context length. A smaller quantized GGUF can be faster or more usable on local hardware, but GGUF alone does not guarantee speed.
Does GGUF lower model quality?
GGUF does not necessarily lower quality. Quantization can. A high-bit GGUF such as F16, BF16, or Q8_0 can preserve more quality, while very low-bit quants may reduce reasoning accuracy.
Can I convert DeepSeek Safetensors to GGUF?
Yes, when the model architecture is supported by llama.cpp or the conversion tool you are using. A common workflow is to convert the Hugging Face model directory with convert_hf_to_gguf.py, then quantize the result with llama-quantize.
Can I convert DeepSeek GGUF back to Safetensors?
You may be able to dequantize or load a GGUF into a framework, but a quantized GGUF cannot recreate the original BF16/FP16 Safetensors weights exactly. Download the original Safetensors checkpoint if you need the real source model.
Why are DeepSeek Safetensors files so large?
Safetensors files often contain original or high-precision model weights. DeepSeek-R1 is a very large MoE model, listed at 671B total parameters with 37B activated parameters, so its full checkpoints are far larger than typical desktop LLM downloads.
What is the best GGUF quantization for DeepSeek?
For many users, Q4_K_M is the best starting point. Use Q5_K_M, Q6_K, or Q8_0 if you have more memory and want better quality. Use lower-bit quants only when your hardware cannot fit larger options.
Is Safetensors safer than GGUF?
Safetensors is specifically designed to avoid pickle-related arbitrary code execution risks when loading model weights. GGUF is a different binary model format used mainly for inference. Safety also depends on the runtime, publisher, and whether you trust the model source.
Can Transformers load GGUF files?
Yes, Transformers documents GGUF loading with the gguf_file parameter for supported models. However, Safetensors is still the standard choice for normal Transformers workflows.
Which DeepSeek format should beginners download?
Beginners who want to chat with DeepSeek locally should download a GGUF model, preferably a distilled model in Q4_K_M or another recommended quant. Beginners who want to learn fine-tuning or model development should start with Safetensors.