Last updated: May 14, 2026
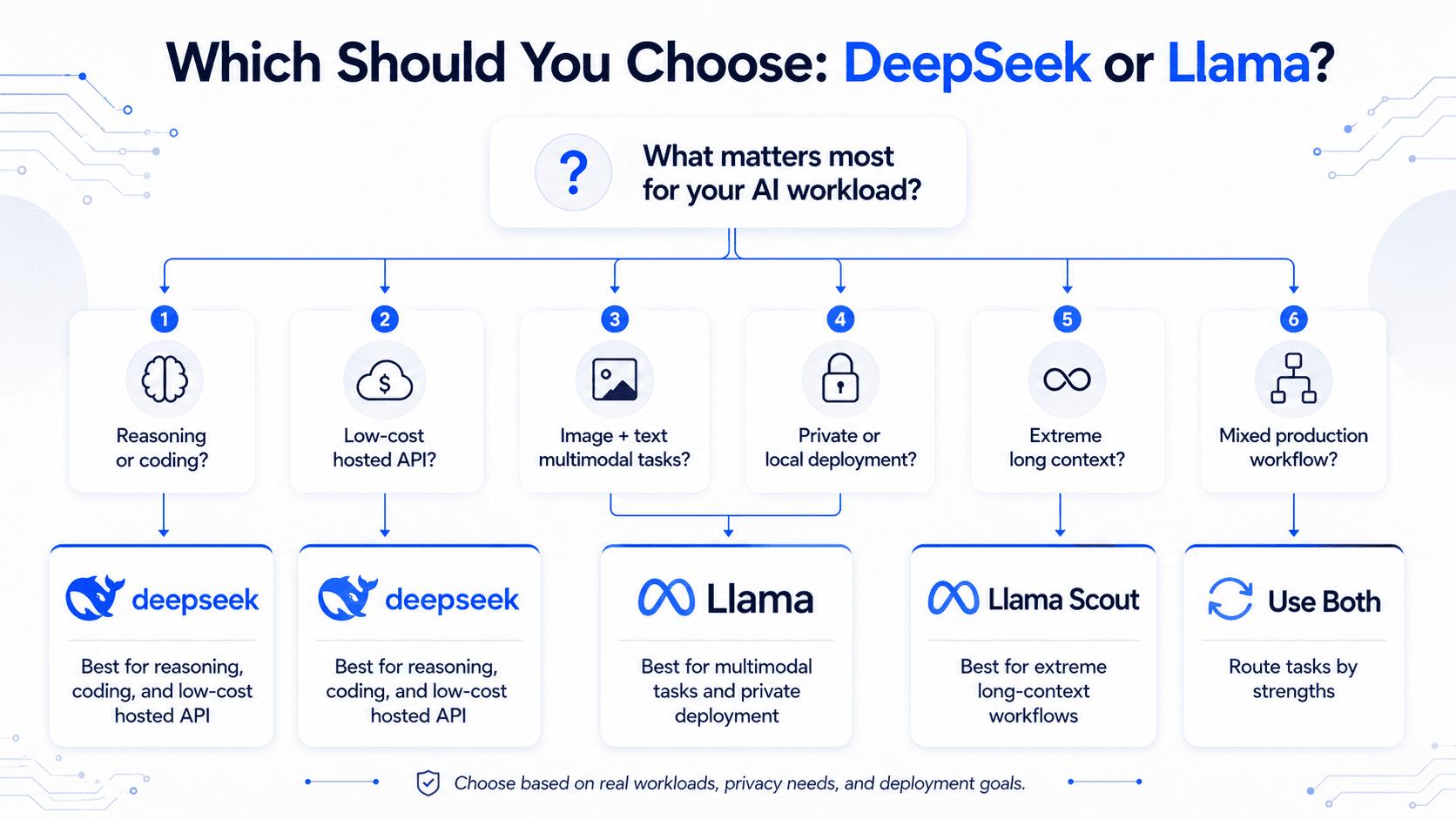
DeepSeek vs Llama is not a simple question of one AI model beating another. It is a comparison between two fast-moving model families: DeepSeek, which is especially strong in reasoning, coding, long-context language tasks, and cost-effective hosted API usage; and Meta’s Llama, which is especially strong for open-weight ecosystem adoption, multimodal text-and-image workflows, self-hosting, long-context experimentation, and enterprise deployment flexibility.
The best choice depends on what you are building. Choose DeepSeek if your priority is advanced reasoning, math, coding agents, low API cost, or million-token text workflows. Choose Llama if you need native multimodal input, broad open-weight infrastructure support, local deployment, or a model family with a large developer ecosystem.
Benchmarks help, but they are not enough. Your own prompts, latency targets, privacy requirements, deployment environment, and total cost of ownership matter more than any single leaderboard score.
Quick Verdict: DeepSeek vs Llama
Best overall answer:
Use DeepSeek for reasoning-heavy, coding-heavy, agentic, and cost-sensitive hosted API workloads. Use Llama for multimodal text-and-image applications, long-context self-hosted workflows, local deployment, and teams that want more control over infrastructure.
DeepSeek’s latest V4 Preview lineup includes DeepSeek-V4-Pro and DeepSeek-V4-Flash, both supporting a 1M-token context length and dual thinking/non-thinking modes through the official API. DeepSeek describes V4-Pro as a 1.6T total / 49B active parameter MoE model and V4-Flash as a 284B total / 13B active parameter MoE model.
Meta’s current Llama 4 family includes Llama 4 Scout and Llama 4 Maverick, both natively multimodal MoE models. Meta’s model card lists Scout as 109B total / 17B active parameters with a 10M-token context length, and Maverick as 400B total / 17B active parameters with a 1M-token context length.
There is no universal winner. DeepSeek is often the stronger pick for reasoning and API economics. Llama is often the stronger pick for multimodality, deployment control, and ecosystem flexibility.
DeepSeek vs Llama: Quick Comparison Table
| Category | DeepSeek | Llama | Winner | Why it matters |
|---|---|---|---|---|
| Latest main models | DeepSeek-V4-Pro, DeepSeek-V4-Flash, with R1/R1-0528 still relevant for reasoning history | Llama 4 Scout, Llama 4 Maverick, with Llama 3.1/3.3 still used in legacy deployments | Tie | Both are model families, not single models. |
| Reasoning and math | DeepSeek V4 and R1 are designed heavily around reasoning, coding, and agentic tasks | Llama 4 Maverick is strong, but Llama’s biggest advantage is not pure reasoning alone | DeepSeek | Better fit for advanced problem solving and code agents. |
| Coding | DeepSeek V4-Pro-Max reports strong scores on LiveCodeBench, Codeforces, SWE Verified, and other coding/agentic benchmarks | Llama 4 Maverick improves over earlier Llama models and supports code output | DeepSeek | Coding agents need reasoning, tool use, and long debugging traces. |
| Multimodal image + text | DeepSeek V4 documentation focuses mainly on language, reasoning, agents, tool calls, and long context | Llama 4 Scout and Maverick are natively multimodal with text and image input | Llama | Best choice when images, charts, screenshots, or visual QA are central. |
| Maximum context length | DeepSeek V4 supports 1M context across official services | Llama 4 Scout supports 10M context; Maverick supports 1M | Llama for max context | Large document, codebase, and multi-document workflows benefit from longer context. |
| Hosted API cost | Official DeepSeek API pricing is aggressive, especially V4-Flash | Llama pricing depends on self-hosting or third-party providers | DeepSeek | Easy win for teams that want a hosted API without running GPUs. |
| Local deployment | DeepSeek V4 weights are available, but the models are large and operationally complex | Llama 4 Scout is explicitly positioned for efficient deployment with quantization; Llama has broad tooling support | Llama | Local deployment is not just weights; it is tooling, serving, quantization, monitoring, and support. |
| Licensing | DeepSeek V4 model weights are listed as MIT licensed on Hugging Face | Llama 4 uses the Llama 4 Community License with conditions | DeepSeek for simplicity | License clarity matters before commercial production use. |
| Enterprise control | Hosted DeepSeek is simple; self-hosted DeepSeek requires serious infrastructure | Llama fits private cloud, on-prem, and regulated deployment strategies well | Llama | Enterprises often need data residency, auditability, and infrastructure control. |
| Best practical approach | Use DeepSeek for reasoning/coding and Llama for multimodal/local workflows | Use both where routing makes sense | Hybrid | Many production AI stacks route tasks to different models. |

What Is DeepSeek?
DeepSeek is a family of AI models from DeepSeek focused on high-performance language modeling, reasoning, coding, tool use, and efficient inference. In 2026, the most important DeepSeek models to consider are DeepSeek-V4-Pro and DeepSeek-V4-Flash.
DeepSeek announced DeepSeek V4 Preview on April 24, 2026, describing it as officially live, open-weight, and built for cost-effective million-token context intelligence. The release lists DeepSeek-V4-Pro at 1.6T total parameters with 49B active parameters, and DeepSeek-V4-Flash at 284B total parameters with 13B active parameters.
DeepSeek V4 is a Mixture-of-Experts model family. That means the model has many total parameters, but only a subset is active for a given token. This helps reduce serving cost compared with a dense model of similar total size. DeepSeek’s V4 model card says the models use a hybrid attention architecture combining compressed and heavily compressed attention to improve long-context efficiency.
DeepSeek also remains known for DeepSeek-R1, a reasoning-focused model family released in 2025. DeepSeek-R1 used large-scale reinforcement learning and was released with distilled models based on Qwen and Llama. The later DeepSeek-R1-0528 release improved complex reasoning, hallucination behavior, function calling, and coding experience according to DeepSeek’s model card.
For most new production evaluations in 2026, start with DeepSeek-V4-Pro for the highest-quality reasoning and agentic workloads, and DeepSeek-V4-Flash for lower-cost, faster, high-volume usage.
What Is Llama?
Llama is Meta’s open-weight large language model family. The current Llama 4 lineup includes Llama 4 Scout and Llama 4 Maverick, both designed as natively multimodal Mixture-of-Experts models.
Meta introduced Llama 4 Scout and Llama 4 Maverick on April 5, 2025, calling them the first open-weight, natively multimodal Llama models with MoE architecture and unprecedented context length support.
The official Llama 4 model card describes Llama 4 models as autoregressive language models using Mixture-of-Experts architecture with early fusion for native multimodality. Llama 4 Scout supports multilingual text and image input, multilingual text and code output, 109B total parameters, 17B active parameters, and a 10M-token context window. Llama 4 Maverick supports multilingual text and image input, multilingual text and code output, 400B total parameters, 17B active parameters, and a 1M-token context window.
One important clarification: Llama is often casually called “open source,” but for production planning it is better to call it open-weight or community-licensed. The Llama 4 model card states that the license is the Llama 4 Community License Agreement, not an unrestricted open-source license.
That distinction matters for enterprises, SaaS companies, and platforms with large user bases.
Model Lineup: DeepSeek V4/R1/V3 vs Llama 4 Scout/Maverick
| Model | Family | Best for | Key details |
|---|---|---|---|
| DeepSeek-V4-Pro | DeepSeek | Advanced reasoning, coding, agentic tasks, long-context language workflows | 1.6T total / 49B active parameters; 1M context; thinking and non-thinking modes |
| DeepSeek-V4-Flash | DeepSeek | Lower-cost API usage, fast reasoning, high-volume workloads | 284B total / 13B active parameters; 1M context; more economical than Pro |
| DeepSeek-R1-0528 | DeepSeek | Reasoning history, math, coding, function calling | Improved version of R1 with stronger reasoning and coding benchmark claims |
| DeepSeek-V3.2 | DeepSeek | Historical reference, efficient reasoning and agentic AI | Important predecessor to V4, but not the first model to test in new 2026 deployments |
| Llama 4 Scout | Llama | Long context, local deployment, multimodal workflows, document analysis | 109B total / 17B active parameters; 10M context; text and image input |
| Llama 4 Maverick | Llama | Higher-quality multimodal assistant use, image understanding, general-purpose apps | 400B total / 17B active parameters; 1M context; text and image input |
| Llama 3.1 / 3.3 | Llama | Legacy deployments, existing fine-tunes, mature tooling | Still useful in many stacks, but no longer the best comparison point for current DeepSeek V4 |
For a current DeepSeek vs Llama article, the right comparison is DeepSeek V4 Pro/Flash vs Llama 4 Scout/Maverick. DeepSeek R1 and Llama 3.1/3.3 should be mentioned only where they explain history, migration paths, or existing deployments.
Architecture and Capabilities
Both DeepSeek and Llama use Mixture-of-Experts design in their latest major families, but they optimize for different priorities.
DeepSeek V4 is built around long-context language efficiency, reasoning modes, and agentic workflows. Its model card says DeepSeek-V4-Pro and DeepSeek-V4-Flash support one-million-token context length, and DeepSeek’s API documentation says the official API supports OpenAI-compatible Chat Completions and Anthropic-compatible interfaces.
Llama 4 is built around native multimodality, long context, and open-weight deployment. Meta’s model card says Llama 4 uses early fusion for multimodality, which means text and image tokens are integrated into a unified model backbone rather than treated as a separate add-on component.
This leads to a practical difference:
DeepSeek feels like the stronger option when the task is “think deeply, reason through code, use tools, solve math, or process a huge text context.”
Llama feels like the stronger option when the task is “understand images, screenshots, charts, documents, or deploy an open-weight model inside our own infrastructure.”
Performance Comparison: Coding, Reasoning, Math, Writing, Multimodal, Long Context
Coding
For coding, DeepSeek has the advantage when you need difficult debugging, code repair, multi-step reasoning, and agent-style software engineering. DeepSeek’s V4 model card reports strong results for V4-Pro-Max on coding and software engineering benchmarks such as LiveCodeBench, Codeforces, SWE Verified, SWE Pro, SWE Multilingual, and Terminal Bench. These are official DeepSeek-reported numbers, so they should be validated on your own tasks.
Llama 4 Maverick is also a capable coding model. Meta’s model card reports Llama 4 Maverick at 43.4 pass@1 on LiveCodeBench for the instruction-tuned model, compared with 32.8 for Llama 4 Scout in the same table.
Winner for coding: DeepSeek for advanced coding agents and difficult reasoning. Llama remains useful for code assistance, especially where local deployment or multimodal inputs matter.
Reasoning and Math
DeepSeek’s biggest advantage is reasoning. DeepSeek-R1 was specifically introduced as a reasoning model trained with large-scale reinforcement learning, and DeepSeek-R1-0528 reported major gains on math and reasoning benchmarks such as AIME 2025, GPQA Diamond, LiveCodeBench, and SWE Verified.
DeepSeek V4 continues that direction with multiple reasoning effort modes: non-think, think, and think max. The model card describes non-think as faster for routine tasks, think as slower but more accurate for complex problem-solving, and think max as the highest reasoning-effort mode.
Llama 4 Maverick also performs strongly in reasoning benchmarks. Meta reports instruction-tuned Llama 4 Maverick at 80.5 on MMLU Pro and 69.8 on GPQA Diamond, compared with 74.3 and 57.2 for Llama 4 Scout.
Winner for reasoning and math: DeepSeek, especially for workloads where explicit reasoning depth matters.
Writing and General Assistant Tasks
For writing, summarization, rewriting, brainstorming, and everyday assistant tasks, the gap is less clear. Llama 4 Maverick is designed as a general-purpose assistant and multimodal model, while DeepSeek-V4-Flash is attractive for high-volume API tasks where cost matters.
Use DeepSeek when the writing task requires technical reasoning, structured analysis, code explanation, or complex planning. Use Llama when the writing task includes images, screenshots, visual references, or a need to deploy inside your own stack.
Winner for writing: Tie. Choose based on deployment and modality needs.
Multimodal Image + Text
This is Llama’s clearest advantage. The Llama 4 model card explicitly lists multilingual text and image as input modalities for Scout and Maverick, and Meta describes Llama 4 as natively multimodal.
DeepSeek V4’s official API pricing page lists JSON output, tool calls, chat prefix completion, and FIM completion, but it does not position V4 as a native image-input model in the same way Llama 4 does.
Winner for multimodal: Llama.
Long Context
DeepSeek V4 gives you a very strong baseline: 1M context across official DeepSeek V4 services.
Llama 4 Scout goes further on maximum context length, with Meta listing a 10M-token context window for Scout and a 1M-token context window for Maverick.
However, context length is not the same as perfect retrieval quality. Long-context performance depends on prompt structure, retrieval design, attention behavior, memory pressure, latency, and where the relevant information appears in the input.
Winner for maximum context: Llama 4 Scout.
Winner for hosted million-token API simplicity: DeepSeek.
Pricing and Total Cost of Ownership
DeepSeek is easier to evaluate on price because it offers official API pricing. As of the current DeepSeek pricing page, prices are listed per 1M tokens. DeepSeek-V4-Flash is listed at $0.0028 per 1M cache-hit input tokens, $0.14 per 1M cache-miss input tokens, and $0.28 per 1M output tokens. DeepSeek-V4-Pro is listed with a temporary 75% discount at $0.003625 per 1M cache-hit input tokens, $0.435 per 1M cache-miss input tokens, and $0.87 per 1M output tokens, with the undiscounted prices shown as $0.0145, $1.74, and $3.48 respectively. DeepSeek notes that prices may vary and should be checked regularly.
Llama pricing is different. Meta provides model weights, but the cost of using Llama depends on where and how you run it. You may pay for:
- GPUs or cloud inference.
- Third-party hosted inference providers.
- Quantization and serving engineering.
- Autoscaling and monitoring.
- Safety tooling.
- Data pipelines and RAG infrastructure.
- Latency optimization.
- Compliance, audit logging, and incident response.
Llama can be cheaper at scale if you already have infrastructure and strong ML operations. It can be more expensive if your team underestimates engineering complexity.
Cost verdict: DeepSeek is usually cheaper and simpler for hosted API usage. Llama can be more cost-effective for teams that can self-host efficiently or negotiate strong third-party inference pricing.
Local Deployment and Hardware Requirements
Llama has the clearer practical advantage for local and private deployment. The Llama 4 Scout model card includes examples for Transformers, vLLM, SGLang, Docker Model Runner, and quantized deployments. It also states that Llama 4 Scout can fit within a single H100 GPU using on-the-fly int4 quantization, while Llama 4 Maverick has FP8 quantized weights that fit on a single H100 DGX host.
DeepSeek V4 can also be run locally, but the models are large and operationally demanding. DeepSeek’s V4 model card recommends referring to its inference folder for local deployment and notes that Think Max reasoning mode should use at least a 384K-token context window.
That is not “download and run on a normal laptop” territory. For serious local DeepSeek V4 deployment, expect large-memory GPU infrastructure, expert serving setup, and careful inference optimization.
Local deployment verdict: Llama is the more practical first choice for most self-hosted teams. DeepSeek is viable for teams with serious infrastructure and a specific need for its reasoning performance.
Licensing and Commercial Use
Licensing is one of the most important differences in the DeepSeek vs Llama decision.
DeepSeek V4’s Hugging Face model card says the repository and model weights are licensed under the MIT License. DeepSeek V3.2’s model card also lists the model weights as MIT licensed.
Llama 4 uses the Llama 4 Community License Agreement. The license grants rights to use, reproduce, distribute, copy, create derivative works, and modify the Llama materials, but it also includes conditions, including attribution requirements and a rule that organizations with more than 700 million monthly active users must request a separate license from Meta.
This is why you should avoid calling Llama “fully open source” in a strict licensing sense. It is better described as open-weight, community-licensed, and commercially usable with conditions.
Licensing verdict: DeepSeek is simpler if MIT licensing applies to the exact model version you use. Llama is widely usable, but legal review is essential before commercial deployment.
Privacy, Security, and Compliance
Privacy depends less on the model name and more on the deployment architecture.
If you use DeepSeek’s hosted API, you are sending prompts and outputs through DeepSeek’s infrastructure. DeepSeek’s privacy policy says it may collect user inputs such as text input, prompts, uploaded files, feedback, and chat history, and that it may use personal data to improve and develop services and train or improve technology. It also says users have the right to opt out of using personal data for training or technology optimization, and that collected personal data may be stored and processed in the People’s Republic of China.
If you self-host Llama, your prompts can stay inside your own cloud, VPC, or on-prem environment. That does not automatically make the deployment compliant, but it gives your team more control over data residency, logging, retention, access controls, and security review.
For regulated industries, the decision framework is simple:
Use hosted DeepSeek only after reviewing its API terms, privacy policy, data processing posture, and your legal obligations. Use self-hosted Llama when you need tighter data residency, private inference, or direct infrastructure control.
Privacy verdict: Llama has the advantage for strict private deployment. DeepSeek can still be appropriate for non-sensitive workloads, public data, internal developer tools, or use cases where the organization has approved the vendor risk profile.
Best Use Cases: When to Choose DeepSeek
Choose DeepSeek when your workload is mostly text, code, reasoning, or agentic execution.
DeepSeek is a strong fit for:
- Coding agents: debugging, repository analysis, code repair, test generation, and SWE-style tasks.
- Math and logic: multi-step reasoning, symbolic tasks, technical analysis, and hard problem solving.
- Agentic workflows: tool use, planning, execution, and reasoning with intermediate steps.
- Cost-sensitive API apps: chatbots, coding tools, internal AI assistants, and SaaS features using a hosted API.
- Million-token text workflows: large document analysis, legal or policy review, technical documentation, and research synthesis.
- Startups: especially teams that need strong capability without building GPU infrastructure.
- RAG systems: when the model must reason across retrieved text chunks and produce structured answers.
- Structured outputs: DeepSeek’s API documentation lists JSON output and tool calls, which are useful for production integrations.
DeepSeek is less ideal when your core product needs native image understanding, strict on-prem deployment, or a huge third-party ecosystem of local serving tools.
Best Use Cases: When to Choose Llama
Choose Llama when you care about deployment control, multimodality, and ecosystem flexibility.
Llama is a strong fit for:
- Multimodal products: image QA, chart explanation, screenshot analysis, document-image understanding, and visual assistants.
- Long-context workflows: especially with Llama 4 Scout’s 10M-token context window.
- Local deployment: private cloud, on-prem, edge-adjacent infrastructure, and controlled inference environments.
- Enterprise compliance: use cases where prompts, logs, and outputs must remain inside your infrastructure.
- Custom fine-tuning and adapters: teams that want to build domain-specific variants.
- RAG and document search: especially when the workflow includes text plus images, tables, or screenshots.
- Developer ecosystem: Llama has broad support across Hugging Face, vLLM, SGLang, Docker workflows, quantization tools, and many inference providers.
Llama is less ideal when you want the simplest possible hosted API pricing, or when your workload is mostly advanced reasoning and coding and you do not want to manage inference infrastructure.
Can You Use Both? Hybrid Workflows
Yes. In many production stacks, the best answer is not DeepSeek or Llama. It is DeepSeek and Llama.
A hybrid architecture might look like this:
- Use DeepSeek-V4-Pro for difficult reasoning, coding agents, math, and complex tool-use workflows.
- Use DeepSeek-V4-Flash for low-cost, high-volume text tasks.
- Use Llama 4 Maverick for multimodal assistant tasks that include image input.
- Use Llama 4 Scout for long-context document workflows or self-hosted use cases.
- Use smaller Llama or distilled models for low-latency internal features.
- Route sensitive workloads to self-hosted models and non-sensitive workloads to hosted APIs.
This model-routing approach is more resilient than betting your entire product on one provider. It lets you optimize by cost, quality, latency, data sensitivity, and modality.
How to Benchmark DeepSeek and Llama Yourself
Do not choose based only on public benchmarks. Benchmarks vary by prompt style, sampling settings, quantization, provider, system prompt, tool-use environment, and deployment setup.
Use this practical testing method:
- Collect 100–300 real prompts from your product or internal workflow.
- Group prompts by task type: coding, reasoning, summarization, RAG, multimodal, tool use, support, classification, extraction.
- Define scoring rubrics: correctness, completeness, latency, cost, hallucination rate, refusal behavior, formatting reliability, and user satisfaction.
- Test the exact versions: for example, DeepSeek-V4-Pro, DeepSeek-V4-Flash, Llama 4 Maverick, and Llama 4 Scout.
- Use production-like settings: same temperature, same max tokens, same retrieval context, same tools, same system prompts.
- Measure total cost: input tokens, output tokens, cache hit rate, GPU time, provider fees, and engineering overhead.
- Run human evaluation: especially for coding, legal, medical, financial, or customer-facing outputs.
- Stress test edge cases: adversarial prompts, long contexts, malformed inputs, multilingual prompts, and empty retrieval results.
- Track regressions over time: model providers change behavior, pricing, context limits, and API compatibility.
A simple leaderboard is not enough. The model that wins your workload is the one that gives the best combination of quality, cost, latency, privacy, and maintainability.

Final Verdict: DeepSeek vs Llama
DeepSeek is the better choice if you want strong reasoning, coding, agentic behavior, million-token text context, and low-cost hosted API access. DeepSeek-V4-Pro is the model to test for high-difficulty reasoning and coding tasks, while DeepSeek-V4-Flash is the model to test for lower-cost production usage.
Llama is the better choice if you want native multimodal input, self-hosting, private deployment, long-context experimentation, and a broad open-weight ecosystem. Llama 4 Maverick is the better Llama model for higher-quality multimodal assistant tasks, while Llama 4 Scout is the better choice for extreme long-context workflows and more efficient deployment.
The most accurate answer to DeepSeek vs Llama is this:
Choose DeepSeek for reasoning and cost-effective hosted intelligence. Choose Llama for multimodal, open-weight, and infrastructure-controlled AI. Use both if your product needs the best of both worlds.
FAQs
1. Is DeepSeek better than Llama?
DeepSeek is usually better for advanced reasoning, math, coding, and agentic tasks. Llama is usually better for multimodal text-and-image workflows, self-hosting, and deployment control. The better model depends on your workload.
2. Is Llama fully open source?
Not in the strictest sense. Llama 4 is best described as open-weight and community-licensed. The Llama 4 model card lists the license as the Llama 4 Community License Agreement, which includes conditions and commercial restrictions for very large platforms.
3. Which is better for coding: DeepSeek or Llama?
DeepSeek is usually the better first choice for coding, especially for debugging, code repair, repository-level reasoning, and coding agents. Llama can still be useful for code generation, especially when local deployment or multimodal inputs are required.
4. Which is better for multimodal tasks?
Llama is the stronger choice for multimodal work because Llama 4 Scout and Maverick officially support text and image input.
5. Which is cheaper: DeepSeek or Llama?
DeepSeek is usually cheaper and simpler for hosted API usage because it has official token-based API pricing. Llama can be cheaper at scale if you self-host efficiently, but GPU, engineering, monitoring, and compliance costs must be included.
6. Can I run DeepSeek locally?
Yes, DeepSeek V4 weights are available and the model cards include local deployment guidance, but the models are large and require serious infrastructure. For many teams, using the official API is simpler.
7. Can I run Llama locally?
Yes. Llama is one of the strongest options for local or private deployment. The Llama 4 model card includes support paths through Transformers, vLLM, SGLang, Docker, and quantization workflows.
8. Which model is better for enterprise compliance?
Llama is often easier for strict enterprise compliance because it can be self-hosted in controlled infrastructure. DeepSeek can still be used by enterprises, but hosted API usage requires vendor, privacy, and data-residency review.
9. Should startups choose DeepSeek or Llama?
Startups should test both. DeepSeek is attractive for quick API-based development and low cost. Llama is attractive when the startup needs local deployment, multimodal features, or model customization.