Last updated: May 14, 2026
The DeepSeek vs Qwen comparison has changed fast. A year ago, most discussions focused on DeepSeek R1 versus Qwen2.5 or Qwen3. Today, the more relevant comparison is DeepSeek V4-Pro and V4-Flash against Qwen3.6-Plus, Qwen3.6-Flash, Qwen3.6-Max-Preview, and the open-weight Qwen3.6 models. Both families now target developers, coding agents, long-context workflows, and cost-sensitive production apps, but they are not identical. DeepSeek is strongest when you want low-cost reasoning and huge context. Qwen is strongest when you want multimodal capability, local deployment flexibility, and Alibaba Cloud integration.
Quick Verdict: DeepSeek vs Qwen
Choose DeepSeek if your priority is cost-efficient reasoning, 1M-token text context, strong open-weight frontier models, or a simple OpenAI/Anthropic-compatible API for coding and reasoning. Choose Qwen if your priority is multimodal apps, smaller open-weight local models, multilingual coverage, built-in tools, and a broader enterprise platform through Alibaba Cloud Model Studio.
DeepSeek V4 Preview launched with V4-Pro and V4-Flash, both supporting a 1M-token context window, while Qwen3.6 focuses heavily on agentic coding, thinking preservation, multimodal support, and practical developer workflows. DeepSeek’s official API pricing is especially aggressive for V4-Flash, while Qwen’s strongest advantage is the breadth of its ecosystem and open models such as Qwen3.6-27B and Qwen3.6-35B-A3B.
| Use case | Better choice | Why |
|---|---|---|
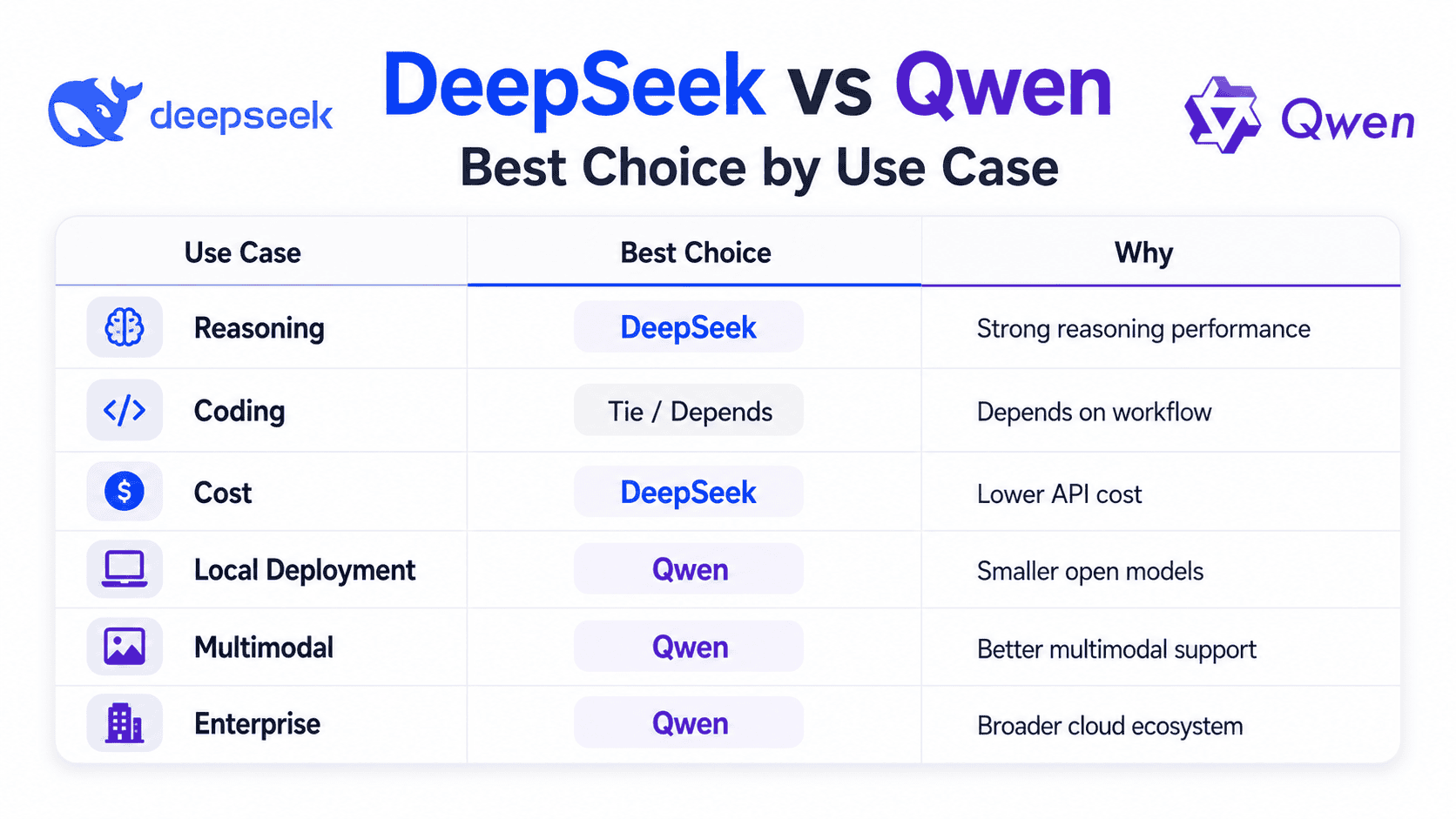
| Best for reasoning | DeepSeek V4-Pro / Qwen3.6-Max-Preview | DeepSeek V4-Pro is strong in reasoning benchmarks; Qwen3.6-Max-Preview is positioned by Alibaba as its stronger proprietary reasoning and agentic model. |
| Best for coding | Tie: DeepSeek for API, Qwen for local/open workflows | DeepSeek V4-Pro performs strongly in coding benchmarks; Qwen3.6-27B and Qwen3.6-35B-A3B are unusually strong open models for coding agents. |
| Best for agentic workflows | Qwen | Qwen3.6 emphasizes agentic coding, thinking preservation, Qwen Code, Qwen Agent, function calling, and built-in tools. |
| Best for long-context tasks | DeepSeek / Qwen3.6-Plus | DeepSeek V4 models support 1M context; Qwen3.6-Plus and Flash also list 1M context in Model Studio. |
| Best for local deployment | Qwen | Qwen3.6-27B and 35B-A3B are more practical than trillion-parameter DeepSeek V4-Pro for local or smaller self-hosted setups. |
| Best for multilingual tasks | Qwen | Qwen’s ecosystem emphasizes broad global language coverage, and Qwen3.6 builds on Qwen3.5’s multilingual foundation. |
| Best for multimodal tasks | Qwen | Qwen3.6 open models include a vision encoder, and Model Studio supports text, image, audio, and video capabilities. |
| Best for API cost | DeepSeek V4-Flash | DeepSeek’s V4-Flash official pricing is lower than Qwen3.6-Plus’s public price range. |
| Best for open-source flexibility | Depends | DeepSeek V4 weights use MIT license; Qwen open-weight models use Apache 2.0. Both are commercial-friendly. |
| Best for enterprise integration | Qwen | Alibaba Cloud Model Studio offers regional deployment modes, official Qwen APIs, OpenAI-compatible APIs, and multimodal model access. |
DeepSeek vs Qwen at a Glance
The table below compares the most relevant 2026 model families rather than older DeepSeek R1 versus Qwen2.5-era comparisons.
| Category | DeepSeek | Qwen |
|---|---|---|
| Developer/company | DeepSeek | Qwen team, Alibaba Group |
| Latest major family | DeepSeek V4 Preview | Qwen3.6 |
| Key models to compare | deepseek-v4-pro, deepseek-v4-flash | qwen3.6-plus, qwen3.6-flash, qwen3.6-max-preview, Qwen3.6-27B, Qwen3.6-35B-A3B |
| Architecture | MoE; V4-Pro is 1.6T total / 49B active, V4-Flash is 284B total / 13B active | Dense and MoE open models; Qwen3.6-35B-A3B is 35B total / 3B active |
| Context window | 1M tokens for V4-Pro and V4-Flash | 1M for Qwen3.6-Plus/Flash; 256K for Qwen3.6-Max-Preview; open models are 262K native and extensible to about 1,010,000 tokens |
| Open-weight availability | Yes, V4 weights available | Yes for Qwen3.6-27B and Qwen3.6-35B-A3B; hosted models vary |
| License | MIT for DeepSeek V4 model weights | Apache 2.0 for Qwen open-weight models |
| API availability | DeepSeek official API | Alibaba Cloud Model Studio |
| API compatibility | OpenAI and Anthropic compatible | OpenAI and Anthropic compatible through Model Studio |
| Multimodal support | V4 is text-focused | Stronger multimodal support; Qwen3.6 open models include vision encoder |
| Tool/function calling | Supported | Supported; some hosted models also support built-in tools |
| Pricing model | Very low V4-Flash pricing; V4-Pro discounted through May 31, 2026 | Qwen3.6-Plus public range; exact pricing varies by model, modality, and region |
| Best use cases | Low-cost reasoning, long-context text, coding API, open-weight frontier experimentation | Multimodal products, local coding agents, multilingual apps, Alibaba Cloud enterprise workflows |
DeepSeek’s official V4 announcement and model card confirm V4-Pro and V4-Flash, the 1M-token context window, and the 1.6T/49B-active and 284B/13B-active model sizes. Qwen’s official repository and Hugging Face cards confirm the Qwen3.6 open models, agentic coding focus, local serving support, context lengths, and Apache 2.0 licensing.
Methodology
This comparison is based on official DeepSeek API docs, DeepSeek Hugging Face model cards, Qwen GitHub and Hugging Face model cards, Alibaba Cloud Model Studio documentation, public pricing pages, and benchmark/evaluation sources. Where benchmark numbers are self-reported by model developers, they are treated as useful but not final. For production decisions, test both models on your own tasks, prompts, tools, latency targets, and compliance requirements.
What Is DeepSeek?
DeepSeek is an AI model developer best known for cost-efficient reasoning and open-weight large language models. In 2026, the most important DeepSeek family for this comparison is DeepSeek V4 Preview, which includes DeepSeek-V4-Pro and DeepSeek-V4-Flash. The official release describes V4-Pro as the larger model and V4-Flash as the faster, more economical option, both with 1M-token context support.
DeepSeek’s main strength is the combination of reasoning performance, long context, and aggressive pricing. The official API page lists V4-Flash at $0.14 per 1M cache-miss input tokens and $0.28 per 1M output tokens, while V4-Pro is listed at a discounted $0.435 input and $0.87 output through May 31, 2026; its non-discounted prices are shown as $1.74 input and $3.48 output. The same page also lists JSON output, tool calls, chat prefix completion, context caching, and a 384K max output limit.
DeepSeek is a strong fit for developers who need reasoning, code generation, large-document analysis, retrieval-augmented generation, and cost-sensitive API usage. It is less compelling if your main requirement is native multimodal input, because DeepSeek V4’s reviewed sources describe text input/output rather than image, audio, or video I/O. Artificial Analysis also lists DeepSeek V4-Pro as text input and text output only.
What Is Qwen?
Qwen is Alibaba’s AI model family. It includes hosted API models through Alibaba Cloud Model Studio, open-weight models on Hugging Face and ModelScope, multimodal models, coding-oriented tools, and agent frameworks. In 2026, the most relevant Qwen family is Qwen3.6, including Qwen3.6-Plus, Qwen3.6-Flash, Qwen3.6-Max-Preview, Qwen3.6-27B, and Qwen3.6-35B-A3B. Qwen’s official GitHub page says Qwen3.6 prioritizes stability, real-world utility, agentic coding, and thinking preservation.
Qwen’s biggest advantage is breadth. Alibaba Cloud Model Studio provides official Qwen APIs, OpenAI-compatible APIs, and multimodal capabilities across text, image, audio, and video. It also supports regional deployment options, where region selection determines where model service access and static data storage happen.
Qwen is especially attractive if you want smaller open-weight models that can be served through Transformers, vLLM, SGLang, llama.cpp, MLX, or similar local inference tools. Qwen’s repository states that Qwen3.6 supports local use through Hugging Face Transformers, llama.cpp, MLX, SGLang, and vLLM, and that open-weight models are licensed under Apache 2.0.
DeepSeek vs Qwen: Performance Comparison
Reasoning and math
DeepSeek V4-Pro is the stronger pick if your workload is mostly text reasoning, hard math, long-context analysis, or code reasoning through the official API. DeepSeek’s model card reports strong results across MMLU-Pro, GPQA Diamond, LiveCodeBench, Codeforces, HMMT, IMOAnswerBench, and other reasoning/coding benchmarks, with separate non-think, high, and max reasoning modes.
Qwen is not weak in reasoning. Qwen3.6-27B reports strong GPQA Diamond, LiveCodeBench, HMMT, IMOAnswerBench, and AIME26 results, and Alibaba positions Qwen3.6-Max-Preview as a stronger proprietary model with better world knowledge, instruction following, and agentic coding than Qwen3.6-Plus. However, many Qwen coding and agent benchmark results are reported using Qwen’s own scaffolds, so treat them as directional rather than universal.
Coding and software engineering
This is the closest category. DeepSeek V4-Pro performs very well on coding benchmarks, including self-reported LiveCodeBench, Codeforces, SWE Verified, SWE Pro, and agentic evaluations. Qwen3.6-27B also reports strong coding-agent numbers, including SWE-bench Verified, SWE-bench Pro, Terminal-Bench 2.0, NL2Repo, QwenWebBench, and Claw-Eval. Qwen’s own notes clarify that some SWE-bench evaluations use an internal agent scaffold and that QwenWebBench is an internal front-end code benchmark, so direct comparisons across labs can be imperfect.
Practical recommendation: use DeepSeek V4-Pro when you want a hosted model for complex coding, reasoning-heavy debugging, and low-cost API use. Use Qwen3.6-27B or Qwen3.6-35B-A3B when you want a local or open-weight coding model with strong multimodal and agentic features.
Agentic workflows and tool use
Qwen has the edge for agentic workflows because the ecosystem is more explicitly designed around tools, coding agents, and multimodal development. Qwen’s official GitHub page points to Qwen Code, an open-source AI agent for the terminal, and Qwen Agent, an open-source framework for LLM applications based on instruction following, tool usage, planning, and memory.
DeepSeek also supports agent tools. Its API docs state that DeepSeek can be used with popular AI agent and coding assistant tools and that the API supports OpenAI/Anthropic-compatible access. For teams that already use Claude Code, OpenCode, or similar tools, DeepSeek can be a strong backend model.
Long-context performance
DeepSeek V4 and Qwen3.6 both compete seriously on long context. DeepSeek V4-Pro and V4-Flash support a 1M-token context window according to official DeepSeek and Hugging Face sources. Qwen3.6-Plus and Qwen3.6-Flash list 1M context in Alibaba Cloud Model Studio docs, while Qwen3.6 open models have a 262,144-token native context and can be extended to about 1,010,000 tokens using long-context methods such as YaRN.
For long legal documents, repositories, or RAG pipelines, DeepSeek V4-Flash is attractive because it combines a large window with low API pricing. For local long-context work, Qwen is often more practical because its 27B and 35B-A3B open models are much smaller than DeepSeek V4-Pro.
Multilingual performance
Qwen is generally the safer choice for multilingual products. The Qwen3.6 repository says Qwen3.6 builds on Qwen3.5, and Qwen3.5’s official description highlights expanded coverage to 201 languages and dialects. DeepSeek is strong in English and Chinese-oriented benchmarks, but Qwen has a broader ecosystem story for global language support.
Multimodal capabilities
Qwen clearly wins for multimodal applications. Qwen3.6-27B and Qwen3.6-35B-A3B are listed as image-text-to-text models with a vision encoder on Hugging Face, and Alibaba Cloud Model Studio supports multimodal capabilities including text, image, audio, and video.
DeepSeek V4 is better understood as a text, reasoning, and coding model. Artificial Analysis lists DeepSeek V4-Pro as supporting text input and text output, and explicitly notes that it is not multimodal.
Writing and general chat quality
For general writing, both families can work well. DeepSeek is often better when the writing task includes reasoning, synthesis, technical explanation, or long-context source analysis. Qwen is often better when the writing task includes multilingual output, visual context, document understanding, or broader Model Studio tooling. The right answer depends less on a generic benchmark and more on your actual content type, prompt style, latency target, and domain.
DeepSeek vs Qwen for Coding
Coding is one of the most important reasons people search for DeepSeek vs Qwen. The decision should not be “which model has the highest single benchmark?” but “which model fits my coding workflow?”
| Coding task | Better choice | Why |
|---|---|---|
| Single-file code generation | Either | Both families are strong; DeepSeek is easy through API, Qwen is strong locally. |
| Debugging with reasoning | DeepSeek V4-Pro | Strong reasoning modes and strong coding benchmark profile. |
| Repository-level coding | Qwen3.6 / DeepSeek V4-Pro | Qwen emphasizes repository-level reasoning; DeepSeek has strong long-context and coding performance. |
| Front-end generation | Qwen3.6 | Qwen’s benchmarks and docs emphasize front-end workflows and QwenWebBench. |
| Local coding assistant | Qwen3.6-27B or 35B-A3B | More practical open-weight sizes and broad local serving support. |
| Low-cost coding API | DeepSeek V4-Flash | Very low official API pricing and 1M context. |
| Coding agent with terminal tooling | Qwen | Qwen Code and Qwen Agent are built around agentic developer workflows. |
| Hard algorithmic reasoning | DeepSeek V4-Pro | Strong self-reported Codeforces, LiveCodeBench, and math-related reasoning results. |
Qwen3.6-27B reports 77.2 on SWE-bench Verified and 59.3 on Terminal-Bench 2.0 in its official card, while Qwen3.6-35B-A3B reports 73.4 on SWE-bench Verified and 51.5 on Terminal-Bench 2.0. Qwen’s card also explains that its SWE-bench series uses an internal agent scaffold, which matters when comparing it with other published results.
DeepSeek V4-Pro reports strong coding and agentic results too, including LiveCodeBench, Codeforces, Terminal Bench 2.0, SWE Verified, SWE Pro, and Toolathlon figures across its high and max reasoning modes. These are promising numbers, but they should still be validated against your own codebase.
DeepSeek vs Qwen for API Developers
Both DeepSeek and Qwen are easy to integrate if you already use OpenAI-style SDKs.
DeepSeek’s API supports OpenAI and Anthropic-compatible formats, and its docs list deepseek-v4-pro and deepseek-v4-flash as the current V4 model IDs. DeepSeek also notes that deepseek-chat and deepseek-reasoner are compatibility aliases for V4-Flash modes and are scheduled for deprecation on July 24, 2026.
Qwen’s official API is provided through Alibaba Cloud Model Studio, which Qwen says is compatible with multiple API specifications, including OpenAI and Anthropic. Alibaba Cloud’s Qwen3.6 docs also list thinking mode, function calling, built-in tools, structured output, and batch calling support by model and region.
Example-style integration decision:
Use DeepSeek if:
- You want the lowest-cost 1M-context text API.
- You need reasoning-heavy code/debugging.
- You want MIT-licensed V4 open weights.
Use Qwen if:
- You need multimodal input.
- You want Alibaba Cloud regional deployment.
- You want Qwen Code, Qwen Agent, built-in tools, or local open-weight coding models.For structured output and tool calls, both families are viable. DeepSeek lists JSON output and tool calls in its API pricing/features table, while Qwen’s Model Studio docs explain function calling, built-in tools, and structured output support.
Pricing and Cost Comparison
Pricing changes frequently, and exact Qwen pricing varies by model, region, modality, and provider. The table below uses official public pricing where available and clearly labels third-party or range-based information.
| Model | Input price per 1M tokens | Output price per 1M tokens | Cached input | Notes |
|---|---|---|---|---|
| DeepSeek V4-Flash | $0.14 cache miss | $0.28 | $0.0028 cache hit | Official DeepSeek pricing; 1M context |
| DeepSeek V4-Pro | $0.435 discounted; $1.74 list | $0.87 discounted; $3.48 list | $0.003625 discounted; $0.0145 list | 75% discount extended to May 31, 2026 |
| Qwen3.6-Plus | $0.5–$2 | $3–$6 | Varies | Public Model Studio page gives a range |
| Qwen3-Coder-Next | $0.3 | $1.5 | Not specified in homepage snippet | Coding-specific hosted model |
| Qwen open-weight models | Self-hosting cost | Self-hosting cost | N/A | Cost depends on GPUs, quantization, throughput, and hosting |
DeepSeek’s pricing table is more explicit for V4 models, while Alibaba Cloud’s public Model Studio page lists Qwen3.6-Plus as $0.5–$2 input and $3–$6 output per 1M tokens. Alibaba’s documentation also warns through its model and deployment pages that features, available models, latency, cost, and default rate limits vary by region and deployment mode.
Cost verdict: DeepSeek V4-Flash is the clearest winner for low-cost API usage. Qwen can still be cheaper in self-hosted workflows if you can run smaller open models efficiently, but that depends on hardware, utilization, and engineering overhead.
Local Deployment and Open-Source Licensing
For local deployment, Qwen is usually easier. Qwen3.6-27B is a 27B model with a vision encoder and 262K native context, extensible to about 1,010,000 tokens. Qwen3.6-35B-A3B is a sparse MoE model with 35B total parameters and 3B activated, also with a vision encoder and the same context profile. Both are Apache 2.0 on Hugging Face.
Qwen also has strong framework support. The official Qwen repo and model cards reference Transformers, vLLM, SGLang, KTransformers, llama.cpp, MLX, GGUF-style local apps, and OpenAI-compatible local serving.
DeepSeek V4 is also open-weight and MIT-licensed, which is excellent for commercial flexibility. However, V4-Pro is a 1.6T-total-parameter model with 49B active parameters, and V4-Flash is 284B total with 13B active. That makes DeepSeek V4 more realistic for serious server infrastructure than for casual laptop deployment. DeepSeek’s Hugging Face card provides local running instructions, but the model scale is still much larger than Qwen3.6-27B or Qwen3.6-35B-A3B.
Local deployment verdict: choose Qwen for local coding assistants, multimodal local experiments, Apple Silicon/MLX workflows, and smaller GPU deployments. Choose DeepSeek if you have the infrastructure to self-host a much larger frontier open-weight model.
Privacy, Safety, and Enterprise Considerations
For privacy, the biggest distinction is not simply DeepSeek versus Qwen. It is hosted API versus self-hosting. If your data is highly sensitive, self-hosting open-weight models may be preferable, regardless of provider.
DeepSeek’s privacy policy says it may collect user input, uploaded files, chat history, device/network data, and other personal data, and that personal data is directly collected, processed, and stored in the People’s Republic of China. It also says personal data may be used to improve and train technology. Enterprises with strict data-residency rules should evaluate this carefully before sending sensitive data to the hosted DeepSeek service.
Alibaba Cloud Model Studio gives more region and deployment-mode options. Its docs say region defines where model service access and static data are stored, and current supported regions include Singapore, US Virginia, China Beijing, China Hong Kong, and Germany Frankfurt. The same docs note that deployment mode affects latency, cost, available models, and default rate limits.
From a safety perspective, do not rely on either model without your own evaluations. Test hallucination rates, refusal behavior, tool-calling reliability, data leakage risk, prompt-injection resistance, and output consistency on your actual workflows.
DeepSeek vs Qwen: Which One Should You Choose?
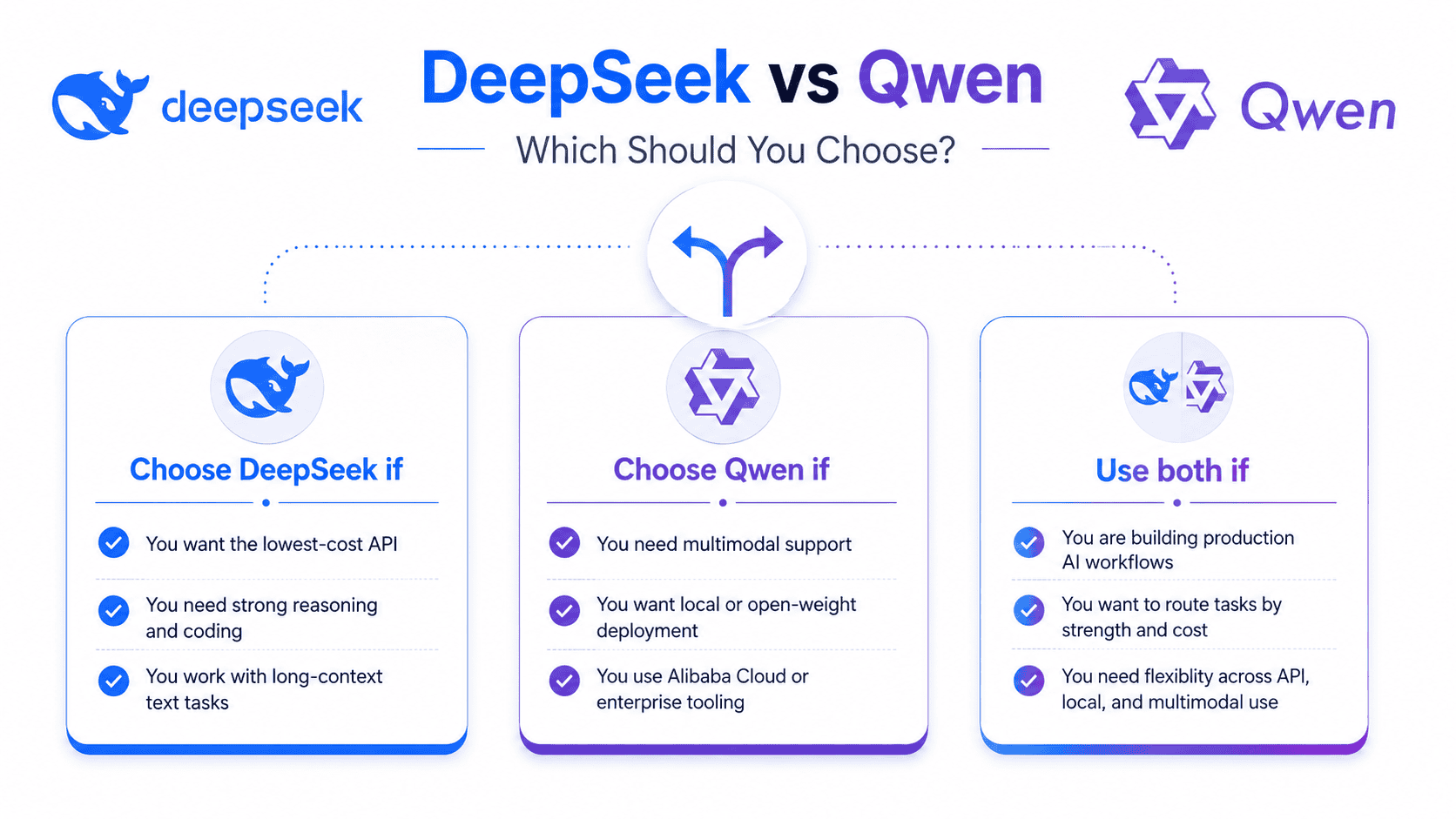
Choose DeepSeek if:
You want the lowest-cost hosted API for long-context text, code reasoning, and general reasoning. DeepSeek V4-Flash is especially attractive for high-volume workloads, while V4-Pro is better for difficult reasoning and coding tasks.
Choose Qwen if:
You need multimodal support, local deployment, smaller open-weight models, multilingual products, Alibaba Cloud integration, or agent tooling such as Qwen Code and Qwen Agent. Qwen3.6-27B and Qwen3.6-35B-A3B are especially compelling for developers who want open-weight coding models without deploying a trillion-parameter system.
Use both if:
You are building production AI systems. A smart architecture is to route long-context text and low-cost reasoning to DeepSeek V4-Flash, harder coding and reasoning to DeepSeek V4-Pro or Qwen3.6-Max-Preview, multimodal tasks to Qwen, and local/private tasks to Qwen3.6 open models.
Avoid choosing based only on benchmarks if:
Your workload involves proprietary code, unusual languages, legal or medical documents, multimodal reasoning, long tool chains, or strict compliance requirements. Benchmarks are useful filters, but production testing matters more.
Final Verdict
In the DeepSeek vs Qwen comparison, DeepSeek is generally stronger for low-cost API reasoning, long-context text processing, and frontier open-weight experimentation. Qwen is generally stronger for multimodal applications, local coding workflows, multilingual products, and enterprise integration through Alibaba Cloud Model Studio.
For most developers, the best answer is not one model forever. Use DeepSeek V4-Flash when cost and 1M context matter, DeepSeek V4-Pro when difficult reasoning and coding matter, Qwen3.6-Plus or Qwen3.6-Max-Preview when you want Alibaba’s hosted agentic ecosystem, and Qwen3.6-27B or Qwen3.6-35B-A3B when you want local or open-weight coding and multimodal workflows.
FAQs About DeepSeek vs Qwen
Is DeepSeek better than Qwen?
DeepSeek is better for low-cost long-context API use, reasoning-heavy text tasks, and frontier open-weight deployment. Qwen is better for multimodal apps, local deployment, multilingual products, and Alibaba Cloud integration.
Is Qwen better than DeepSeek for coding?
Qwen can be better for local coding agents and multimodal developer workflows, especially with Qwen3.6-27B and Qwen3.6-35B-A3B. DeepSeek V4-Pro can be better for hosted API coding, hard reasoning, and algorithmic debugging.
Which is cheaper, DeepSeek or Qwen?
For official hosted API usage, DeepSeek V4-Flash is cheaper than Qwen3.6-Plus based on public pricing. Qwen can be cost-effective when self-hosted, but that depends on GPU cost and utilization.
Can I run DeepSeek and Qwen locally?
Yes, both have open-weight options. Qwen is generally easier to run locally because Qwen3.6-27B and Qwen3.6-35B-A3B are much smaller than DeepSeek V4-Pro. DeepSeek V4 is open-weight but requires more serious infrastructure.
Is DeepSeek open source?
DeepSeek V4 is open-weight, and its Hugging Face model card says the repository and model weights are licensed under the MIT License. That makes it commercially flexible, but deployment requirements remain significant.
Is Qwen open source?
Some Qwen models are open-weight. The Qwen3.6 repository states that its open-weight models are licensed under Apache 2.0. Hosted Qwen models such as Qwen3.6-Plus or Qwen3.6-Max-Preview are API models rather than open-weight releases.
Which is better for reasoning?
DeepSeek V4-Pro is often the better first choice for text-only reasoning and math-heavy work. Qwen3.6-Max-Preview is a strong alternative if you are already using Alibaba Cloud Model Studio or need Qwen’s agentic tooling.
Which is better for multilingual tasks?
Qwen is usually the better choice for multilingual products because the Qwen family emphasizes broad language coverage and global deployment. DeepSeek is strong in English and Chinese, but Qwen has the broader multilingual ecosystem.
Which is better for API developers?
DeepSeek is simpler if you want a low-cost OpenAI/Anthropic-compatible text API. Qwen is better if you want Model Studio, built-in tools, multimodal models, regional deployment options, and broader enterprise cloud integration.
Is DeepSeek R1 better than Qwen?
DeepSeek R1 was historically important for reasoning, but in 2026 the better comparison is DeepSeek V4 versus Qwen3.6. R1 is no longer the only DeepSeek model developers should consider.
Is Qwen3.6 better than DeepSeek V4?
Qwen3.6 is better for multimodal, local, and agentic ecosystem use cases. DeepSeek V4 is better for low-cost long-context text reasoning and hosted API efficiency. Neither is universally better.
Which model should startups use?
Startups should test both. Use DeepSeek V4-Flash for low-cost API workloads, DeepSeek V4-Pro for hard reasoning, Qwen3.6 open models for local coding and privacy-sensitive workflows, and Qwen3.6-Plus or Max-Preview for multimodal and Alibaba Cloud apps.