Last reviewed: May 1, 2026
DeepSeek Docker Deployment can mean three different things: packaging an app that calls the hosted DeepSeek API, running a local DeepSeek-related model through Docker Model Runner or Ollama, or self-hosting DeepSeek weights with GPU inference servers such as vLLM or SGLang. For most production apps, the hosted DeepSeek API inside Docker is the simplest and safest path.
DeepSeek’s current API supports OpenAI- and Anthropic-compatible formats, with OpenAI-format base URL https://api.deepseek.com and current V4 model names including deepseek-v4-flash and deepseek-v4-pro. The older deepseek-chat and deepseek-reasoner names are compatibility aliases scheduled for deprecation on July 24, 2026.
Quick Answer
- Use Docker to package your application, gateway, or local model stack.
- Use the hosted DeepSeek API for the easiest production deployment.
- Store
DEEPSEEK_API_KEYin environment variables, Docker secrets, or a managed secret store.- Use Docker Model Runner or Ollama + Open WebUI for local DeepSeek R1/distill experimentation.
- Use vLLM or SGLang only when you have suitable GPU infrastructure.
- Never expose Ollama, Open WebUI, vLLM, SGLang, or LiteLLM publicly without authentication and TLS.
- Verify model names, Docker image tags, and pricing before deployment.
DeepSeek Docker Deployment Options Compared
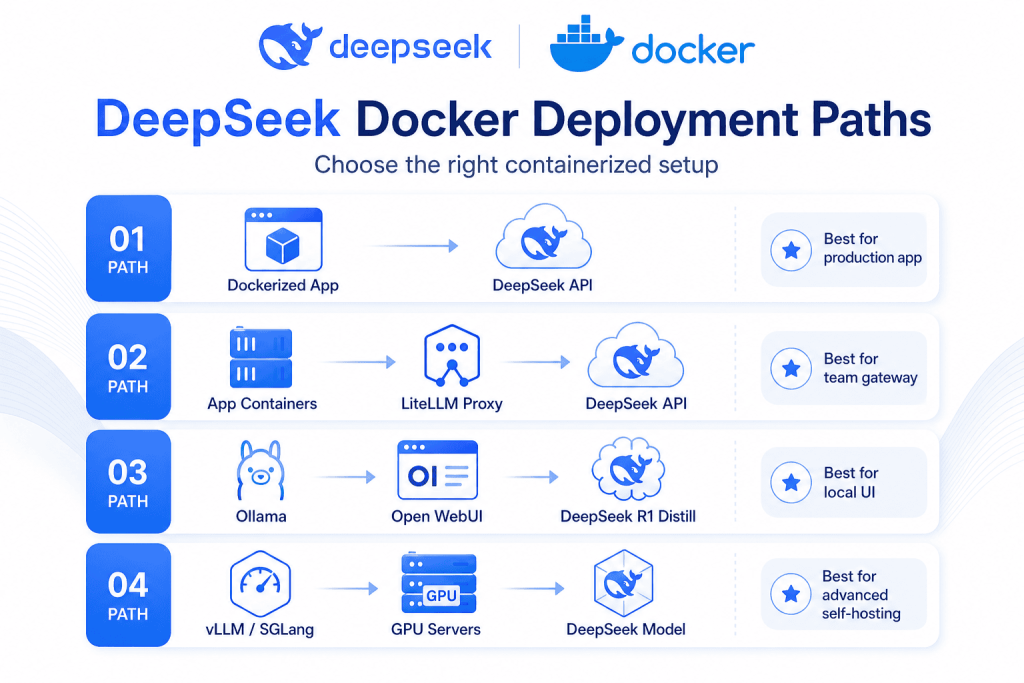
| Deployment path | Best for | Runs model locally? | Requires GPU? | Complexity | Recommended use |
|---|---|---|---|---|---|
| Dockerized app calling DeepSeek API | SaaS apps, backends, internal tools | No | No | Low | Default production path |
| LiteLLM proxy container with DeepSeek upstream | Teams, routing, virtual keys, spend tracking | No | No | Medium | Team gateway |
| Docker Model Runner with DeepSeek/R1 distill model | Local development and offline-style tests | Yes | Optional | Low-medium | Local prototypes |
| Ollama + Open WebUI with DeepSeek model | Private local chat UI | Yes | Optional, recommended for larger models | Low-medium | Local experimentation |
| vLLM Docker self-hosting | High-throughput inference on GPU servers | Yes | Yes | High | Advanced infrastructure teams |
| Kubernetes / production GPU cluster | Scale, HA, multi-node serving | Yes | Yes | Very high | Platform teams |
| API-only local development using Docker Compose | Testing API apps locally | No | No | Low | Fast app development |
What Does “DeepSeek Docker Deployment” Actually Mean?
The phrase DeepSeek Docker is ambiguous. It usually means one of these:
| Meaning | What you deploy | Best path |
|---|---|---|
| API app deployment | Your app runs in Docker and calls DeepSeek’s hosted API | FastAPI/Node app + Docker Compose |
| Local model deployment | A smaller DeepSeek-related model runs on your machine | Docker Model Runner or Ollama |
| Self-hosted inference | DeepSeek weights run on your own GPU servers | vLLM or SGLang |
Docker packages software, but it does not reduce model size or VRAM requirements. Full DeepSeek V4 self-hosting is not a casual laptop deployment. DeepSeek V4 Pro is listed as a 1.6T-parameter MoE model with 49B active parameters, while DeepSeek V4 Flash is listed as a 284B-parameter MoE model with 13B active parameters; both support a 1M-token context window.
Which Path Should You Choose?
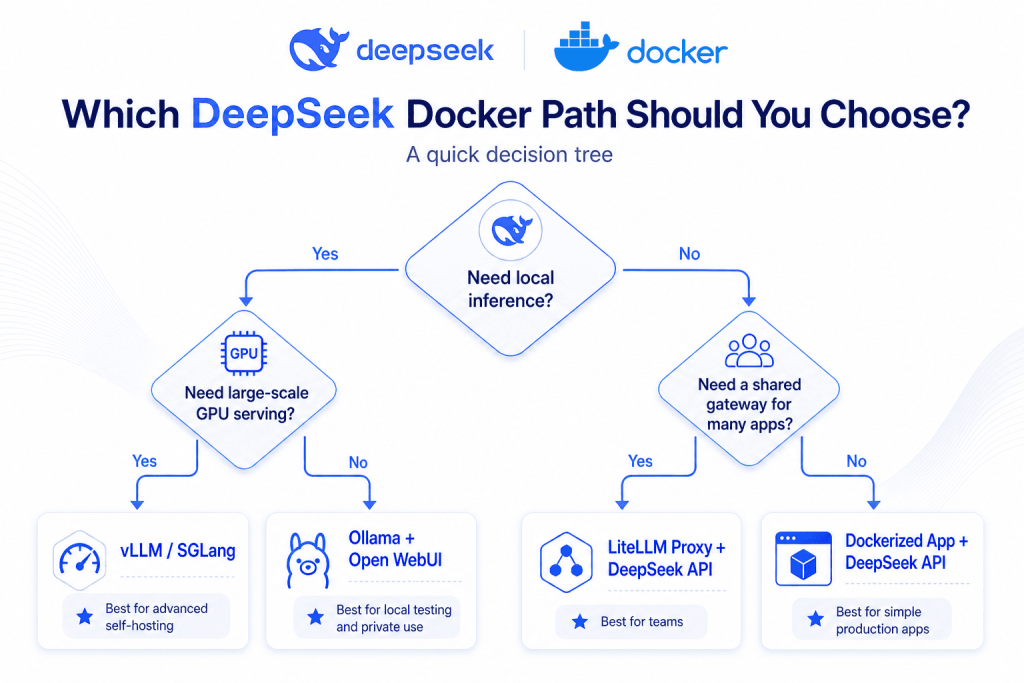
| Situation | Choose this |
|---|---|
| You are building a web app or backend | Dockerized app calling DeepSeek API |
| You have multiple apps or teams | LiteLLM proxy in front of DeepSeek |
| You want local experiments without API cost | Docker Model Runner or Ollama |
| You want a browser chat UI | Ollama + Open WebUI |
| You need full control over inference | vLLM or SGLang on GPU infrastructure |
| You are unsure | Start with the hosted API path |
Prerequisites
You do not need every item below. Pick the requirements for your chosen path.
- Docker Engine or Docker Desktop.
- Docker Compose v2, using
docker compose, not legacydocker-compose. - A DeepSeek account and API key for the hosted API path.
- LiteLLM if you want an internal gateway or proxy.
- Docker Model Runner if you want packaged local model execution.
- Ollama and Open WebUI if you want a local chat stack.
- A Hugging Face token if your self-hosted model download requires authentication.
- NVIDIA GPU driver and NVIDIA Container Toolkit for GPU containers.
- Enough disk, RAM, and VRAM for the selected model.
- A small test project.
Docker Model Runner can serve models through OpenAI- and Ollama-compatible APIs and can package GGUF model files as OCI artifacts. It supports llama.cpp, vLLM, and Diffusers engines, with vLLM requiring NVIDIA GPUs on supported platforms.
Open WebUI is a self-hosted AI platform that supports Ollama and OpenAI-compatible APIs, while its Docker quick start explicitly recommends Docker Compose v2 syntax.
The Model Names You Must Not Confuse
| Context | Example model name | What it means | Use case |
|---|---|---|---|
| DeepSeek API | deepseek-v4-flash | Hosted API model | Production app calls |
| DeepSeek API | deepseek-v4-pro | Hosted API model | Complex reasoning/API workloads |
| Hugging Face | deepseek-ai/DeepSeek-V4-Flash | Open-weight model repo | Advanced self-hosting |
| Hugging Face | deepseek-ai/DeepSeek-V4-Pro | Open-weight model repo | Advanced GPU self-hosting |
| Docker Model Runner | ai/deepseek-r1-distill-llama | Packaged local distill model | Local development |
| Ollama | deepseek-r1:8b, deepseek-r1:32b, etc. | Ollama model tags | Local experimentation |
DeepSeek’s API docs list deepseek-v4-flash and deepseek-v4-pro as the current API models and mark deepseek-chat and deepseek-reasoner for deprecation.
The Docker Hub ai/deepseek-r1-distill-llama model is a Docker-published DeepSeek R1 distill Llama model, not the same thing as the hosted DeepSeek V4 API model. Its listed tags include 8B-Q4_0, 8B-Q4_K_M, 8B-F16, 70B-Q4_0, and 70B-Q4_K_M.
Method 1 — Dockerize an App That Calls the DeepSeek API
This is the recommended DeepSeek Docker Deployment for most production teams. You deploy your own app in Docker, and the app calls DeepSeek through the hosted API.
What You Will Build
A small FastAPI service with one /chat endpoint:
deepseek-api-app/
├─ app/
│ └─ main.py
├─ .env.example
├─ requirements.txt
├─ Dockerfile
└─ docker-compose.yml.env.example
DEEPSEEK_API_KEY=sk-your-key-here
DEEPSEEK_BASE_URL=https://api.deepseek.com
DEEPSEEK_MODEL=deepseek-v4-flashNever commit the real .env file.
requirements.txt
fastapi
uvicorn[standard]
openai
pydanticapp/main.py
import os
from typing import Optional
from fastapi import FastAPI, HTTPException
from openai import OpenAI
from pydantic import BaseModel
class ChatRequest(BaseModel):
prompt: str
system: Optional[str] = "You are a helpful coding assistant."
app = FastAPI(title="DeepSeek Docker API App")
def get_client() -> OpenAI:
api_key = os.getenv("DEEPSEEK_API_KEY")
if not api_key:
raise RuntimeError("DEEPSEEK_API_KEY is not set")
return OpenAI(
api_key=api_key,
base_url=os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com"),
)
@app.get("/healthz")
def healthz():
return {"status": "ok", "has_api_key": bool(os.getenv("DEEPSEEK_API_KEY"))}
@app.post("/chat")
def chat(request: ChatRequest):
model = os.getenv("DEEPSEEK_MODEL", "deepseek-v4-flash")
try:
client = get_client()
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": request.system},
{"role": "user", "content": request.prompt},
],
max_tokens=500,
stream=False,
extra_body={
"thinking": {"type": "disabled"}
},
)
return {
"model": model,
"answer": response.choices[0].message.content,
}
except Exception as exc:
raise HTTPException(status_code=500, detail=str(exc))DeepSeek’s own quick start shows the OpenAI-compatible /chat/completions format with model, messages, optional thinking, reasoning_effort, and stream.
Dockerfile
FROM python:3.12-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN addgroup --system app && adduser --system --ingroup app app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY app ./app
USER app
EXPOSE 8000
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]docker-compose.yml
services:
app:
build: .
env_file:
- .env
ports:
- "8000:8000"
restart: unless-stopped
healthcheck:
test: ["CMD", "python", "-c", "import urllib.request; urllib.request.urlopen('http://localhost:8000/healthz')"]
interval: 30s
timeout: 5s
retries: 3Run It
cp .env.example .env
# edit .env and add your real key
docker compose up --build -d
docker compose logs -f app
Test the Local App
curl http://localhost:8000/chat \
-H "Content-Type: application/json" \
-d '{
"prompt": "Explain Docker healthchecks in two sentences."
}'Direct DeepSeek API Smoke Test
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{"role": "user", "content": "Reply with OK if the API works."}
],
"thinking": {"type": "disabled"},
"max_tokens": 20,
"stream": false
}'Production Secret Handling
For local development, .env is acceptable. For production, prefer Docker secrets or your cloud secret manager. Docker Compose secrets are mounted inside the container under /run/secrets/<secret_name> and are granted to services explicitly.
Method 2 — Add a LiteLLM Proxy for DeepSeek
LiteLLM is useful when you want one internal OpenAI-compatible endpoint in front of DeepSeek. It can help with virtual keys, spend tracking, rate limits, logging, observability, model routing, and easier provider switching.
LiteLLM documents DeepSeek through provider-qualified model strings such as deepseek/deepseek-reasoner, and its proxy uses a model_list where model_name is the client-facing alias and litellm_params.model is the provider model string.
litellm-config.yaml
model_list:
- model_name: deepseek-v4-flash
litellm_params:
model: deepseek/deepseek-v4-flash
api_key: os.environ/DEEPSEEK_API_KEY
- model_name: deepseek-v4-pro
litellm_params:
model: deepseek/deepseek-v4-pro
api_key: os.environ/DEEPSEEK_API_KEY
general_settings:
master_key: os.environ/LITELLM_MASTER_KEYThis config follows LiteLLM’s documented deepseek/<model> provider pattern and DeepSeek’s current V4 model names. If your LiteLLM version has not yet recognized the V4 names, upgrade LiteLLM or route DeepSeek as an OpenAI-compatible provider.
.env
DEEPSEEK_API_KEY=sk-your-deepseek-key
LITELLM_MASTER_KEY=sk-change-this-admin-key
LITELLM_SALT_KEY=sk-generate-a-stable-random-salt
POSTGRES_PASSWORD=change-this-passwordLiteLLM’s production guidance says the salt key is used to encrypt and decrypt stored LLM credentials and should not be changed after adding models.
docker-compose.yml
services:
litellm-db:
image: postgres:16-alpine
environment:
POSTGRES_DB: litellm
POSTGRES_USER: litellm
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
volumes:
- litellm_db:/var/lib/postgresql/data
restart: unless-stopped
litellm:
image: docker.litellm.ai/berriai/litellm:main-latest
depends_on:
- litellm-db
ports:
- "4000:4000"
env_file:
- .env
environment:
DATABASE_URL: postgresql://litellm:${POSTGRES_PASSWORD}@litellm-db:5432/litellm
volumes:
- ./litellm-config.yaml:/app/config.yaml:ro
command: ["--config", "/app/config.yaml", "--port", "4000"]
restart: unless-stopped
volumes:
litellm_db:LiteLLM’s deployment docs list the official Docker image and Docker Compose options, and its virtual-key docs require a database, DATABASE_URL, and a master key for proxy key management.
Test Through LiteLLM
docker compose up -d
curl http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${LITELLM_MASTER_KEY}" \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{"role": "user", "content": "Give me one Docker hardening tip."}
],
"max_tokens": 100
}'Do not expose the LiteLLM proxy directly to the public internet without authentication, TLS, rate limits, and access controls.
Method 3 — Run DeepSeek Locally with Docker Model Runner
Docker Model Runner is best when you want a local model workflow with Docker-native commands. It can serve local models through OpenAI-, Anthropic-, and Ollama-compatible APIs.
This path is usually for DeepSeek R1/distill-style models, not the hosted DeepSeek V4 API models.
Enable Docker Model Runner
In Docker Desktop, enable Docker Model Runner from the AI settings. With Docker Engine, install the Docker Model Runner plugin and test it with docker model version or docker model run ai/smollm2.
Pull a DeepSeek R1 Distill Model
docker model pull ai/deepseek-r1-distill-llama:8B-Q4_K_M
docker model listDocker Hub currently lists ai/deepseek-r1-distill-llama under Docker’s verified publisher namespace with multiple tags, including 8B and 70B quantized variants.
Run It Interactively
docker model run ai/deepseek-r1-distill-llama:8B-Q4_K_MCall It Through the OpenAI-Compatible API
From the host:
curl http://localhost:12434/engines/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/deepseek-r1-distill-llama:8B-Q4_K_M",
"messages": [
{"role": "user", "content": "Explain Docker volumes in one paragraph."}
]
}'Docker’s API reference says OpenAI-compatible clients should use the /engines/v1 path and specify the full model identifier, including namespace.
Calling Docker Model Runner from Another Container
For Docker Desktop containers, use:
http://model-runner.docker.internal/engines/v1For Docker Engine containers, add this to the Compose service:
extra_hosts:
- "model-runner.docker.internal:host-gateway"Then use:
http://model-runner.docker.internal:12434/engines/v1Docker documents different base URLs for host processes and containers, and notes the extra_hosts workaround for Compose projects on Docker Engine.
Method 4 — Run DeepSeek with Ollama + Open WebUI in Docker
Use this path when you want a private local chat UI and you are comfortable using local model variants such as DeepSeek R1 distill tags.
Ollama’s Docker docs provide CPU-only, NVIDIA GPU, AMD GPU, and Vulkan examples. For NVIDIA GPU, Ollama tells users to install NVIDIA Container Toolkit and run the container with --gpus=all.

docker-compose.yml
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
ports:
- "11434:11434"
volumes:
- ollama:/root/.ollama
restart: unless-stopped
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
depends_on:
- ollama
ports:
- "3000:8080"
environment:
OLLAMA_BASE_URL: http://ollama:11434
WEBUI_SECRET_KEY: change-this-secret
volumes:
- open-webui:/app/backend/data
restart: unless-stopped
volumes:
ollama:
open-webui:Docker Compose supports GPU reservations with deploy.resources.reservations.devices, where capabilities is required and gpu is a recognized capability.
For CPU-only systems, remove the entire deploy: block from the ollama service.
Start the Stack
docker compose up -d
docker compose logs -f ollamaPull a DeepSeek Model in Ollama
docker exec -it ollama ollama pull deepseek-r1:8bOllama’s library lists DeepSeek R1 tags including 1.5b, 7b, 8b, 14b, 32b, 70b, and 671b; the model size you choose must fit your hardware.
Open your browser at:
http://localhost:3000Then create your account, verify the Ollama connection, and select the pulled DeepSeek model.
Stop or Remove the Stack
docker compose downTo delete local Open WebUI data and Ollama model volumes:
docker compose down -vOpen WebUI’s Docker Compose quick start uses docker compose up -d and documents docker compose down and docker compose down -v for uninstalling, with the warning that volume deletion removes data.
Method 5 — Advanced: Self-Host DeepSeek Weights with vLLM Docker
This is the advanced path. Use it only when you have serious GPU infrastructure, inference-serving experience, and a reason to self-host.
vLLM announced support for the DeepSeek V4 family on April 24, 2026, and describes V4 Pro as the larger 1.6T-parameter model and V4 Flash as the smaller roughly 285B-parameter model, both supporting up to 1M context.
vLLM Docker Baseline
vLLM’s official Docker deployment docs use the vllm/vllm-openai image, mount the Hugging Face cache, pass HF_TOKEN, publish port 8000, and use --ipc=host.
A generic vLLM Docker pattern looks like this:
export HF_TOKEN=your-huggingface-token
docker run --gpus all \
--ipc=host \
-p 8000:8000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HF_TOKEN=${HF_TOKEN}" \
vllm/vllm-openai:latest \
--model deepseek-ai/DeepSeek-V4-Flash \
--trust-remote-codeFor DeepSeek V4 specifically, use the current vLLM recipe or blog command for your GPU architecture. vLLM’s DeepSeek V4 blog gives a V4 Pro command for 8×B200 or 8×B300 and a V4 Flash command for 4×B200 or 4×B300, with flags such as --kv-cache-dtype fp8, --enable-expert-parallel, --data-parallel-size, --tokenizer-mode deepseek_v4, --tool-call-parser deepseek_v4, and --reasoning-parser deepseek_v4.
Example: vLLM DeepSeek V4 Flash Pattern
docker run --gpus all \
--ipc=host \
-p 8000:8000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
vllm/vllm-openai:deepseekv4-cu130 deepseek-ai/DeepSeek-V4-Flash \
--trust-remote-code \
--kv-cache-dtype fp8 \
--block-size 256 \
--enable-expert-parallel \
--data-parallel-size 4 \
--tokenizer-mode deepseek_v4 \
--tool-call-parser deepseek_v4 \
--enable-auto-tool-choice \
--reasoning-parser deepseek_v4Do not blindly copy this into a random server. Match the image tag, GPU architecture, model variant, parallelism settings, and vLLM recipe to your hardware.
vLLM’s recipe page for DeepSeek V4 Pro mentions reasoning modes and notes that Think Max requires --max-model-len >= 393216 to avoid truncation; it also lists 8×B300 and 8×H200 deployment notes, with H200 context capped at 800K tokens in the recipe to leave KV headroom.
SGLang Alternative
SGLang also documents DeepSeek V4 deployment, including hardware-specific Docker images for B300, B200, GB200/GB300, and H200, plus a minimal Docker pattern with --gpus all, --shm-size, Hugging Face cache, HF_TOKEN, and --ipc=host.
For most teams, the hosted DeepSeek API or a managed inference platform is simpler than self-hosting V4.
GPU Setup for Docker
Start on the host:
nvidia-smiIf that fails, fix the host driver first. Then install and configure NVIDIA Container Toolkit.
NVIDIA’s current install guide shows installing nvidia-container-toolkit, configuring Docker with sudo nvidia-ctk runtime configure --runtime=docker, and restarting Docker.
Test GPU passthrough:
sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smiNVIDIA’s sample workload documentation uses that command to verify that Docker can access the GPU after the driver and toolkit are installed.
Common GPU failures:
| Error | Likely cause | Fix |
|---|---|---|
could not select device driver | NVIDIA runtime not configured | Install toolkit, run nvidia-ctk, restart Docker |
nvidia-container-cli not found | Toolkit missing or broken | Reinstall NVIDIA Container Toolkit |
| CUDA mismatch | Driver/runtime incompatibility | Use a container image compatible with your host driver |
| Container sees no GPUs | Missing --gpus all or Compose GPU reservation | Add GPU flags and verify nvidia-smi |
| vLLM OOM | Model/context too large | Lower context, use more GPUs, choose smaller model |
Production Hardening Checklist
Before shipping DeepSeek Docker Deployment to production:
- Pin image tags instead of using
latest. - Do not commit
.env. - Use Docker secrets or cloud secret managers.
- Run containers as non-root where possible.
- Add healthchecks and readiness checks.
- Use restart policies.
- Log request IDs, latency, model name, and errors.
- Add rate limits.
- Put public endpoints behind TLS and authentication.
- Restrict Open WebUI, Ollama, vLLM, SGLang, and LiteLLM to private networks unless secured.
- Persist model/cache data with volumes.
- Avoid pulling huge weights during every deployment.
- Scan images in CI/CD.
- Document model names, model versions, pricing assumptions, and hardware assumptions.
Cost, Privacy, and Performance Trade-Offs
| Path | Cost model | Privacy | Performance | Best fit |
|---|---|---|---|---|
| Hosted DeepSeek API | Token billing | Sends prompts/code to provider | Managed by provider | Most apps |
| LiteLLM proxy + DeepSeek API | Token billing + proxy infra | Same provider exposure, better internal control | Good for teams | Multi-service orgs |
| Docker Model Runner | Local hardware cost | Local prompts | Depends on model/hardware | Local development |
| Ollama + Open WebUI | Local hardware cost | Local prompts | Depends on model/hardware | Private chat UI |
| vLLM self-hosted | GPU capex/opex | Highest control | High if tuned well | Infra teams |
| Managed GPU cloud | GPU rental + storage | Depends on cloud/provider | High, variable | Teams avoiding hardware |
DeepSeek’s pricing page bills by input and output tokens. At the time reviewed, it listed V4 Flash at $0.0028 per 1M cache-hit input tokens, $0.14 per 1M cache-miss input tokens, and $0.28 per 1M output tokens; V4 Pro was listed with a temporary 75% discount through May 31, 2026. DeepSeek also warns that prices may vary and recommends checking the page regularly.
Self-hosting can be more expensive than API usage if your workloads are intermittent. GPU servers still cost money while idle, and long-context inference can require expensive memory even when the model weights are open.
Common Errors and Fixes
| Error / Symptom | Likely cause | Fix |
|---|---|---|
| 401 Unauthorized | Wrong DeepSeek API key | Recreate key and update .env or secret store |
| 402 insufficient balance | No API balance | Top up or reduce usage |
| 429 rate limit | Too many requests | Add backoff, queueing, or rate limits |
| Model not found | Wrong model name | Use deepseek-v4-flash or deepseek-v4-pro for API |
| Wrong DeepSeek base URL | Used OpenAI URL | Use https://api.deepseek.com |
| API key baked into image | Secret copied in Dockerfile | Rotate key and pass it at runtime |
.env not loaded | Compose file missing env_file | Add env_file: .env or environment variables |
| Port already in use | Another service uses 3000/4000/8000/11434 | Change port mapping |
docker compose not found | Old Docker install | Install Compose v2 plugin |
| Ollama starts but model missing | Model not pulled | Run docker exec -it ollama ollama pull deepseek-r1:8b |
| Open WebUI cannot connect to Ollama | Wrong service URL | Use OLLAMA_BASE_URL=http://ollama:11434 inside Compose |
| Docker Model Runner endpoint unreachable | Wrong host/container URL | Use documented host/container base URL |
model-runner.docker.internal not resolving | Docker Engine Compose network issue | Add extra_hosts mapping |
| NVIDIA GPU not visible | Toolkit/runtime not configured | Run NVIDIA sample workload |
| CUDA mismatch | Driver/image mismatch | Use compatible CUDA/vLLM image |
| vLLM OOM | Model or context too large | Reduce --max-model-len, increase GPUs, use Flash |
| Hugging Face token missing | Gated download or auth needed | Pass HF_TOKEN |
| vLLM startup slow | Huge model download/load | Persist HF cache volume |
| Context length too high | KV cache pressure | Lower max model length |
| Public local endpoint exposed | No auth/TLS | Restrict network and add reverse proxy |
| Full V4 does not fit expected hardware | Model is very large | Use API, smaller model, or proper GPU cluster |
deepseek-chat / deepseek-reasoner issues | Deprecated aliases | Migrate to V4 model IDs |
| Thinking/reasoning mode issues | Client does not handle reasoning fields | Disable thinking or update client |
DeepSeek’s error-code page lists 401 for authentication failure, 402 for insufficient balance, 429 for rate limits, 500 for server error, and 503 for server overload.
Recommended Deployment Patterns
Pattern A — Single App Container → DeepSeek API
Best for SaaS apps, backend APIs, internal tools, and production teams that want simple operations.
Browser / client
↓
Your app container
↓
DeepSeek hosted APIUse this first unless you have a clear reason not to.
Pattern B — App Container → LiteLLM Proxy → DeepSeek API
Best for teams that need virtual keys, budgets, routing, rate limits, and spend tracking.
App containers
↓
LiteLLM proxy
↓
DeepSeek APILiteLLM documents virtual keys for spend tracking and model access control, and its spend-tracking docs cover key, user, and team spend across providers.
Pattern C — Open WebUI/Ollama or Docker Model Runner Local Stack
Best for local prototypes, demos, private experiments, and offline-style development.
Open WebUI or local app
↓
Ollama / Docker Model Runner
↓
Local DeepSeek-related modelUse this for local experimentation, not as a substitute for the hosted V4 API unless your model, hardware, and quality requirements match.
Pattern D — vLLM or SGLang GPU Inference Server
Best for advanced self-hosted inference teams.
Apps
↓
Internal gateway / load balancer
↓
vLLM or SGLang GPU servers
↓
DeepSeek V4 weightsThis path needs GPU planning, cache strategy, model versioning, monitoring, autoscaling, and cost analysis.
FAQ
What is DeepSeek Docker Deployment?
DeepSeek Docker Deployment means using Docker to run either an app that calls the hosted DeepSeek API, a local DeepSeek-related model stack, or a GPU inference server that self-hosts DeepSeek weights.
Can I run DeepSeek in Docker?
Yes. You can run an app that calls DeepSeek in Docker, run local DeepSeek R1/distill models with Docker Model Runner or Ollama, or self-host open weights with vLLM/SGLang on suitable GPUs.
What is the easiest DeepSeek Docker setup?
The easiest setup is a Dockerized app that calls the hosted DeepSeek API using https://api.deepseek.com and deepseek-v4-flash.
Can I run DeepSeek V4 locally with Docker?
Technically yes, because DeepSeek V4 weights are available, but full V4 self-hosting is an advanced GPU deployment. It is not a simple laptop Docker command.
Is DeepSeek Docker free?
Docker may be free depending on your usage and license, but DeepSeek API calls are token-billed. Local models avoid API token billing but still require hardware, storage, electricity, and operations time.
Should I use DeepSeek API or run a local model?
Use the DeepSeek API for production simplicity and current V4 access. Use local models when privacy, offline experimentation, or cost control for small workloads matters more than hosted-model quality.
What is the DeepSeek API base URL for Docker apps?
Use https://api.deepseek.com for OpenAI-compatible SDKs and https://api.deepseek.com/anthropic for Anthropic-compatible clients.
How do I pass a DeepSeek API key into Docker securely?
For development, use .env with env_file. For production, use Docker secrets, your orchestrator’s secret store, or a cloud secret manager. Never copy the key into the image.
Can I use Docker Compose with DeepSeek?
Yes. Docker Compose is useful for a single app, an app plus LiteLLM proxy, Ollama + Open WebUI, or multi-container local development.
How do I run DeepSeek with Ollama and Open WebUI?
Run Ollama and Open WebUI in Docker Compose, set OLLAMA_BASE_URL to http://ollama:11434, then pull a model such as deepseek-r1:8b inside the Ollama container.
Does Docker Model Runner support DeepSeek?
Docker Hub lists ai/deepseek-r1-distill-llama as a Docker-published model with 8B and 70B tags, but this is a DeepSeek R1 distill model, not the hosted DeepSeek V4 API.
Can I self-host DeepSeek with vLLM Docker?
Yes, for advanced GPU environments. vLLM documents Docker deployment through vllm/vllm-openai, and vLLM has DeepSeek V4-specific guidance for large GPU setups.
Why does my container not see the NVIDIA GPU?
Usually the host driver, NVIDIA Container Toolkit, Docker runtime configuration, or --gpus all setting is missing. Verify with nvidia-smi on the host and NVIDIA’s sample Docker workload.
Is it safe to expose Ollama, Open WebUI, vLLM, or LiteLLM publicly?
Not without authentication, TLS, network restrictions, monitoring, and rate limits. Treat these endpoints as sensitive infrastructure.
What is the difference between deepseek-v4-flash and ai/deepseek-r1-distill-llama?
deepseek-v4-flash is a hosted DeepSeek API model ID. ai/deepseek-r1-distill-llama is a Docker Model Runner model package for local R1 distill experimentation.
Conclusion
For most production users, the best DeepSeek Docker Deployment is simple: containerize your app and call the hosted DeepSeek API with deepseek-v4-flash or deepseek-v4-pro. Add LiteLLM when you need team-level keys, routing, spend tracking, and model governance.
Use Docker Model Runner or Ollama + Open WebUI for local experimentation with DeepSeek R1/distill-style models. Use vLLM or SGLang only when you have the GPU infrastructure and operational experience to self-host large DeepSeek weights safely.
The practical default is: Dockerized API app for production, LiteLLM for teams, Docker Model Runner or Ollama for local experiments, and vLLM/SGLang for advanced GPU self-hosting only.