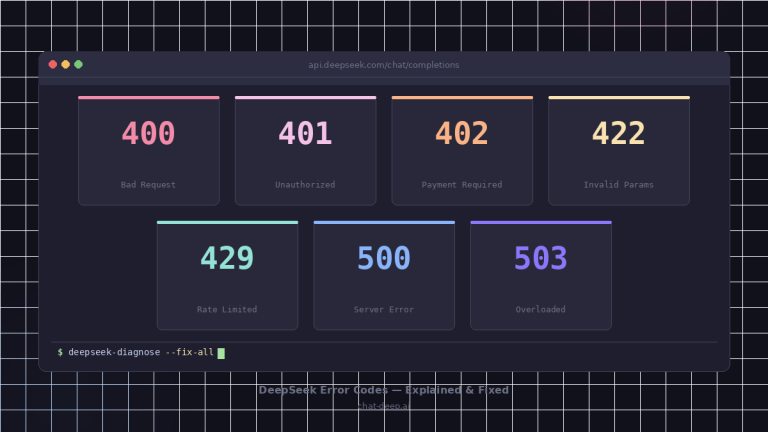
DeepSeek token usage refers to the actual input and output tokens recorded by the API for each request, and these values are the only source of truth for billing. Unlike rough character-based estimates, real cost is calculated directly from the usage object returned in the API response, including cache-hit input, cache-miss input, and output tokens.
What this page is (and is not):
This page explains how to read DeepSeek API usage and turn it into real cost.
For official rates, see the pricing page. For estimation before sending requests, use the cost calculator.
Last verified: April 5, 2026
Current official state (last verified on April 5, 2026)
- Current hosted API version: DeepSeek-V3.2
- deepseek-chat: stable API alias currently mapped to DeepSeek-V3.2 non-thinking mode
- deepseek-reasoner: stable API alias currently mapped to DeepSeek-V3.2 thinking mode
- Context length: 128K
- Input price (cache hit): $0.028 / 1M tokens
- Input price (cache miss): $0.28 / 1M tokens
- Output price: $0.42 / 1M tokens
- Actual billed usage comes from the API response
- Offline token estimates are approximate only
This summary reflects the current official docs: the pricing page maps both public aliases to DeepSeek‑V3.2 with a 128K context limit, the token page says actual processed tokens come from the model’s return, and the chat-completions schema defines the usage object used for request accounting.
Token usage is one of the easiest DeepSeek topics to misunderstand. The official token page is intentionally introductory, while the real accounting detail lives in the chat-completions schema. Pricing, context caching, and thinking mode all shape how you should interpret usage, which is why this page should sit between your API guide, pricing page, calculator, and thinking-mode guide rather than duplicate any one of them.
This guide focuses on how DeepSeek API actually counts and bills tokens in production. If you need official pricing details or want to estimate costs before sending requests, see our DeepSeek pricing guide or use the API cost calculator.
What DeepSeek means by “tokens”
In DeepSeek’s docs, tokens are the basic units the model uses to process text, and they are also the billing unit. DeepSeek explains that a token can be a word, a number, or even punctuation, and the token page adds that people can think of tokens roughly as characters or words for intuition only.
The official token page gives approximate conversion ratios such as about 0.3 token per English character and 0.6 token per Chinese character. But the same page immediately warns that tokenization differs by model and that the actual number of processed tokens is based on the model’s return.
That distinction matters for both engineers and finance teams. Offline estimates are useful for planning prompt size, but they are not the final ledger once a request hits production. The API response is.
Approximate token estimates vs actual billed usage
Offline estimates help answer rough planning questions like “Is this prompt closer to 2,000 tokens or 20,000?” They are useful in draft tooling, budget previews, and prompt editors. DeepSeek even provides an offline tokenizer package for that purpose.
But actual billed usage comes from the API response. The official token page says the actual processed tokens are based on the model’s return, and the chat-completions schema is where DeepSeek defines the authoritative fields that represent request usage.
| Source | What it tells you | Best use case | Where it can mislead |
|---|---|---|---|
| Offline estimate | Approximate token count before a request | Early planning, budget forecasting, prompt drafting | Can differ from real billed usage |
API usage object | Actual token accounting for the request | Billing, dashboards, cost alerts, production monitoring | Only available after the request runs |
The practical rule is simple: estimate before sending, but account after the response arrives. That is the safest way to avoid budgeting from rough text length alone.
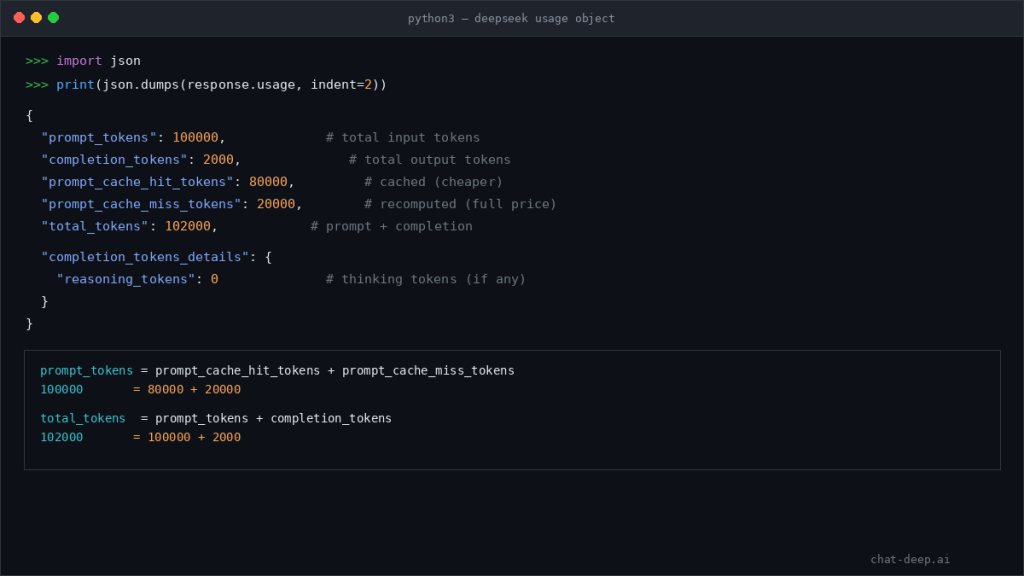
The DeepSeek usage object explained
The usage object is the core accounting block in DeepSeek’s chat-completions response. DeepSeek currently defines completion_tokens, prompt_tokens, prompt_cache_hit_tokens, prompt_cache_miss_tokens, total_tokens, and completion_tokens_details.reasoning_tokens. The same schema states that prompt_tokens = prompt_cache_hit_tokens + prompt_cache_miss_tokens, and that total_tokens is prompt plus completion.
| Field | What it means | Why it matters |
|---|---|---|
prompt_tokens | Total input-side tokens in the request | Core input size metric |
completion_tokens | Total output-side tokens generated | Main output cost driver |
prompt_cache_hit_tokens | Prompt tokens served from cache | Cheaper input bucket |
prompt_cache_miss_tokens | Prompt tokens recomputed normally | More expensive input bucket |
total_tokens | Prompt + completion tokens | Simple request-size summary |
completion_tokens_details.reasoning_tokens | Tokens generated for reasoning | Useful for interpreting thinking-heavy workloads |
If you only log total_tokens, you lose the most useful detail about where spend came from. DeepSeek’s current schema is rich enough that most teams should store the full usage breakdown, not just the headline total.
Prompt tokens vs completion tokens
Prompt tokens are the input side of the request. They include your system instructions, prior messages, reusable context, examples, and the current user turn. Completion tokens are the output side: the text the model generates in response. DeepSeek’s schema separates those fields directly, and the pricing page says billing is based on the total number of input and output tokens used by the model.
These two sides affect cost differently. Long prompts can drive large input bills, especially when cache misses are high. Long outputs can drive large output bills even when the prompt is moderate. You need both sides to understand the real economics of a request.
Cache-hit and cache-miss prompt tokens explained
DeepSeek does not bill all prompt tokens as one single bucket. On the current hosted API, the pricing page splits input into two categories: 1M input tokens (cache hit) and 1M input tokens (cache miss), each with a different public price. The response schema mirrors that split with prompt_cache_hit_tokens and prompt_cache_miss_tokens.
That matters because repeated-prefix reuse can sharply reduce input cost. DeepSeek’s context-caching guide says caching is enabled by default, and that only the repeated prefix portion of subsequent requests can become a cache hit. So prompt size alone is not enough; you also need to know how much of that prompt reused cached prefix work and how much did not.
For a deeper explanation of how prefix reuse affects cost, see our DeepSeek context caching guide.
Reasoning tokens explained
completion_tokens_details.reasoning_tokens is DeepSeek’s current field for tokens generated by the model for reasoning. In the schema, it sits inside completion_tokens_details, which DeepSeek describes as the breakdown of tokens used in a completion.
The important nuance is that DeepSeek does not publish a separate official price line for reasoning tokens. The current public price table still lists only cache-hit input, cache-miss input, and output tokens. But thinking-heavy requests can still cost more in practice when they generate more completion-side tokens or run with much larger output allowances. That is an inference from the current docs, not a separate pricing announcement.
That inference is grounded in two current facts. First, the schema exposes reasoning tokens as part of the completion breakdown. Second, the pricing page shows that deepseek-reasoner has a much larger default and maximum output budget than deepseek-chat while sharing the same per-token public rate table.
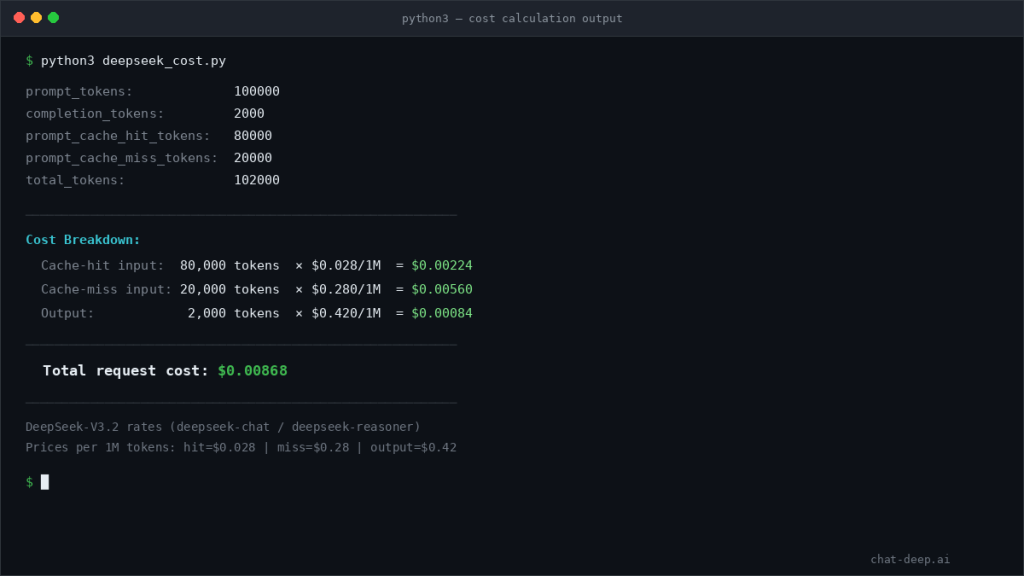
Current pricing and how to compute request cost from live usage
On the current hosted API, both deepseek-chat and deepseek-reasoner map to DeepSeek‑V3.2 with a 128K context limit. The pricing page currently lists the same public rates for both aliases: $0.028 / 1M cache-hit input tokens, $0.28 / 1M cache-miss input tokens, and $0.42 / 1M output tokens.
That means the cleanest cost formula comes directly from the response fields:
request_cost =
(prompt_cache_hit_tokens / 1_000_000 * 0.028) +
(prompt_cache_miss_tokens / 1_000_000 * 0.28) +
(completion_tokens / 1_000_000 * 0.42)
Example:
prompt_cache_hit_tokens = 80,000prompt_cache_miss_tokens = 20,000completion_tokens = 2,000
cost =
(80,000 / 1,000,000 * 0.028) +
(20,000 / 1,000,000 * 0.28) +
(2,000 / 1,000,000 * 0.42)
cost = 0.00224 + 0.00560 + 0.00084
cost = $0.00868
For planning across many requests, your pricing page and API cost calculator are still the right tools. But for truth at the per-request level, the response usage object is the actual accounting source.
Non-streaming vs streaming token usage
In standard non-streaming responses, usage arrives directly in the response object. That is the simplest case for billing, dashboards, and per-request logs. DeepSeek’s response examples show usage inline on non-streaming chat completions.
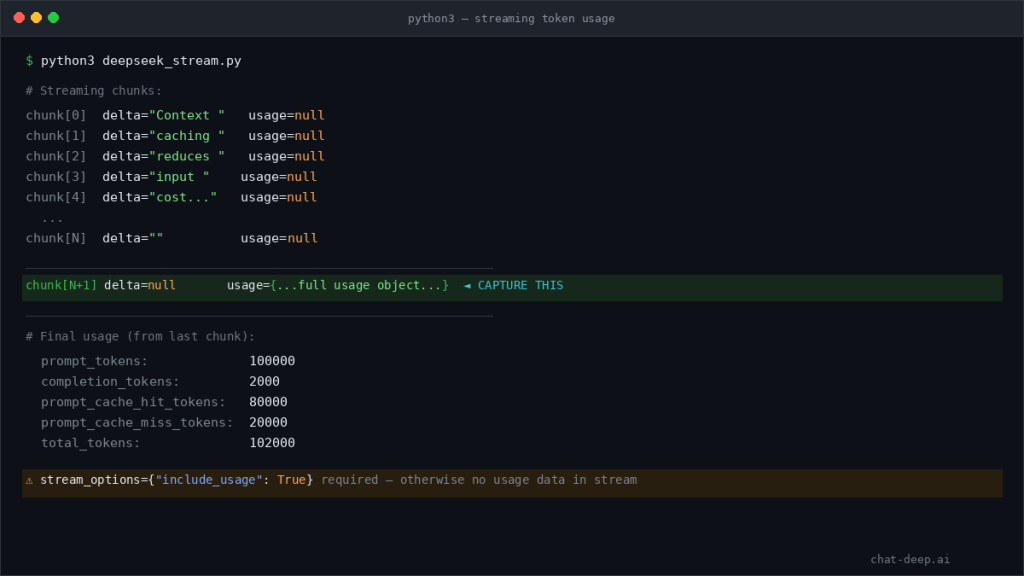
In streaming mode, usage handling is different. DeepSeek’s current chat-completions docs say that when you set stream_options.include_usage, the API sends an additional chunk before [DONE] that contains the full request-level usage, while the normal streamed chunks include a usage field with null.
If you stream responses but never capture the final usage chunk, your accounting will be incomplete. That is one of the easiest observability gaps to create in production chat systems.
A simple implementation example
The example below follows the current DeepSeek accounting model: request a completion, read usage, and compute cost from the currently published rates.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_DEEPSEEK_API_KEY",
base_url="https://api.deepseek.com",
)
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a concise assistant."},
{
"role": "user",
"content": "Summarize the main benefits of context caching in one paragraph.",
},
],
)
usage = response.usage
prompt_tokens = usage.prompt_tokens
completion_tokens = usage.completion_tokens
prompt_cache_hit_tokens = getattr(usage, "prompt_cache_hit_tokens", 0)
prompt_cache_miss_tokens = getattr(usage, "prompt_cache_miss_tokens", 0)
total_tokens = usage.total_tokens
cost = (
prompt_cache_hit_tokens / 1_000_000 * 0.028
+ prompt_cache_miss_tokens / 1_000_000 * 0.28
+ completion_tokens / 1_000_000 * 0.42
)
print("prompt_tokens:", prompt_tokens)
print("completion_tokens:", completion_tokens)
print("prompt_cache_hit_tokens:", prompt_cache_hit_tokens)
print("prompt_cache_miss_tokens:", prompt_cache_miss_tokens)
print("total_tokens:", total_tokens)
print(f"estimated_request_cost: ${cost:.8f}")
This is the right default pattern for accounting: read the fields, compute cost from the published rates, and log the result alongside application metadata.
A simple streaming example
DeepSeek’s streaming docs say the final usage-bearing chunk only appears if you ask for it with stream_options.include_usage. That is why the code below watches for the one chunk where usage is not null.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_DEEPSEEK_API_KEY",
base_url="https://api.deepseek.com"
)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain token usage briefly."}
]
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
stream=False
)
usage = response.usage
print("prompt_tokens:", usage.prompt_tokens)
print("completion_tokens:", usage.completion_tokens)
print("total_tokens:", usage.total_tokens)
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "YOUR_DEEPSEEK_API_KEY",
baseURL: "https://api.deepseek.com"
});
const response = await client.chat.completions.create({
model: "deepseek-chat",
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Explain token usage briefly." }
]
});
console.log(response.usage);The key point is not the syntax. It is the discipline: ignore usage: null on ordinary chunks and capture the final usage-bearing chunk for complete accounting.
Common mistakes and debugging
One of the biggest mistakes is treating character estimates as final billed usage. DeepSeek explicitly presents those ratios as approximate and says the actual token count is based on the model’s return.
Another is assuming all prompt tokens cost the same. They do not. On the current pricing table, cache-hit input and cache-miss input have different rates, and the schema exposes both buckets separately.
A third mistake is ignoring reasoning_tokens and then being surprised by the cost of thinking-heavy requests. The docs do not announce a separate reasoning surcharge, but reasoning-heavy flows can still cost more in practice because they can generate more completion-side tokens and run within larger output limits.
Streaming creates its own trap. If you never capture the final usage chunk, your logs may show content but not full request-level token accounting.
Production best practices
Log the full set of important usage fields for every request: prompt, completion, cache hit, cache miss, total, and reasoning tokens when present. DeepSeek’s current schema is rich enough that most teams should not settle for total_tokens alone.
Separate dashboards into input, output, cache reuse, and reasoning-heavy workflows. Budget from observed production usage, not just theoretical prompt sizes. Use the pricing guide and calculator for planning, but use live usage data for truth.
Cap output intentionally with max_tokens, review prompt changes for cost impact, and monitor thinking-heavy flows separately from standard chat. That recommendation follows directly from the current rate model, the larger output allowances on the reasoning surface, and the fact that reasoning tokens are visible in the completion breakdown.
DeepSeek token usage vs rough token estimation
Many developers rely on offline token estimators, but these tools are only approximations. DeepSeek’s API billing is based exclusively on the usage object returned after each request. This means two prompts with similar length can produce different billed usage depending on caching, model behavior, and output size.
FAQ
What is DeepSeek token usage?
It is the token accounting returned by the API for each request, covering input, output, cache reuse, and total request size.
What is the difference between prompt_tokens and completion_tokens?
prompt_tokens are the input-side tokens you send. completion_tokens are the output-side tokens the model generates.
What are prompt_cache_hit_tokens and prompt_cache_miss_tokens?
They split prompt usage into reused prefix tokens versus recomputed input tokens, and together they add up to prompt_tokens.
What are reasoning_tokens in DeepSeek?
They are tokens generated by the model for reasoning and are exposed inside completion_tokens_details.reasoning_tokens.
Are reasoning tokens billed separately?
DeepSeek does not currently publish a separate official price line for reasoning tokens. They matter because reasoning-heavy requests can increase completion-side usage in practice.
Why can thinking mode cost more in practice?
Because it can generate more completion-side tokens, use larger output budgets, and surface reasoning-heavy behavior even under the same published token-rate table. That is an inference from the current schema and pricing docs, not a separate published surcharge.
Why does my approximate token estimate not match billed usage?
Because offline token estimates are only rough planning tools. The actual billed usage is determined by the model response.
How do I calculate DeepSeek request cost from the response object?
Use the live usage fields and apply the current public rates for cache-hit input, cache-miss input, and output tokens.
How do I get token usage in streaming responses?
Use stream_options={"include_usage": True} and capture the final extra chunk that contains the full request-level usage.
Does DeepSeek charge for cached tokens?
Yes, but at a lower rate. Cached input tokens (prompt_cache_hit_tokens) are billed at a significantly reduced price compared to non-cached input tokens (prompt_cache_miss_tokens).