DeepSeek is an AI model family and developer ecosystem that emphasizes open-weight releases alongside hosted API access. DeepSeek has open-sourced key releases (for example, the DeepSeek-R1 series) under the MIT License, enabling self-hosting, auditing, and adaptation inside your own infrastructure.
For API users, DeepSeek provides both a standard chat mode and a reasoning-focused mode that can return a separate reasoning_content field alongside the final answer. This makes multi-step reasoning workflows more inspectable. The current flagship model, DeepSeek V3.2, supports a 128K context window and unifies chat and reasoning in a single model.
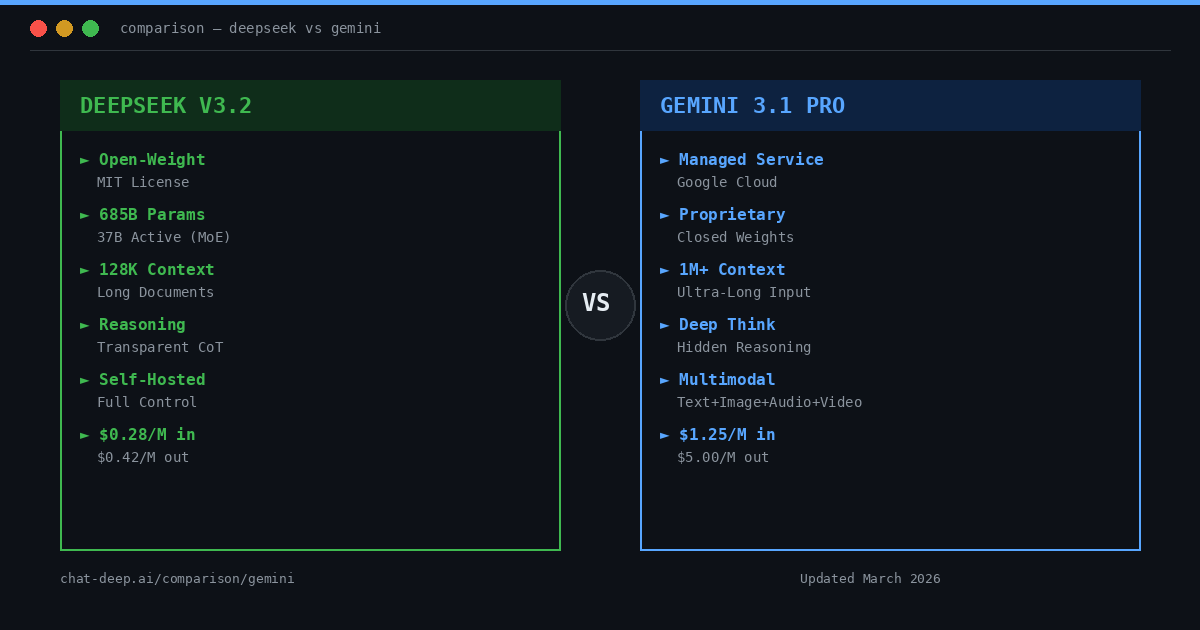
Google’s Gemini models represent a managed-service approach. Developers access them through Google’s cloud platforms (such as Vertex AI) rather than through downloadable model weights. The current flagship is Gemini 3.1 Pro, released February 19, 2026, replacing the earlier Gemini 3 Pro Preview which was deprecated and shut down on March 9, 2026.
In this article, Gemini is used as a structural reference point to clarify how DeepSeek’s open-weight options and reasoning-transparent API differ from a managed, proprietary model service.
(Note: chat-deep.ai is an independent community resource, not affiliated with DeepSeek or Google.)
DeepSeek Architecture
DeepSeek’s architecture prioritizes long-context workflows and explicit support for both direct answers and step-by-step reasoning.
DeepSeek V3.2: Technical Specifications
The current flagship model is DeepSeek V3.2, released in December 2025. It is a 685-billion-parameter Mixture-of-Experts (MoE) model with 37 billion parameters active per token, built on the V3.1-Terminus checkpoint. Key specifications include:
- 685B total parameters / 37B active — efficient MoE routing keeps inference costs manageable
- 128K token context window — suitable for long documents, code files, and multi-turn conversations
- DeepSeek Sparse Attention (DSA) — reduces training and inference cost while preserving long-context quality
- Unified chat and reasoning — a single model handles both direct answers and chain-of-thought reasoning
- Gold-medal benchmarks — achieved gold on the 2025 IMO and IOI competitions
- MIT License — permitting unrestricted commercial use, modification, and redistribution
V3.2 unified what were previously separate endpoints. Earlier releases required choosing between deepseek-chat (direct answers) and deepseek-reasoner (chain-of-thought). V3.2 merges both, with reasoning toggled via a simple parameter.
The MoE architecture is what keeps V3.2 practical despite its massive 685B parameter count. Rather than activating the entire model on every token, MoE routes each input to a small subset of specialized “expert” sub-networks. Only 37B parameters are active per token, meaning inference costs stay manageable and the model can run on hardware configurations that would be impossible for a dense model of equivalent capability.
The DeepSeek Sparse Attention (DSA) mechanism further improves efficiency. Traditional transformer attention scales quadratically with sequence length. DSA reduces this by selectively attending to relevant portions of the input, cutting both training and inference costs while maintaining output quality. This is particularly important for the 128K context window, where full attention would be prohibitively expensive.
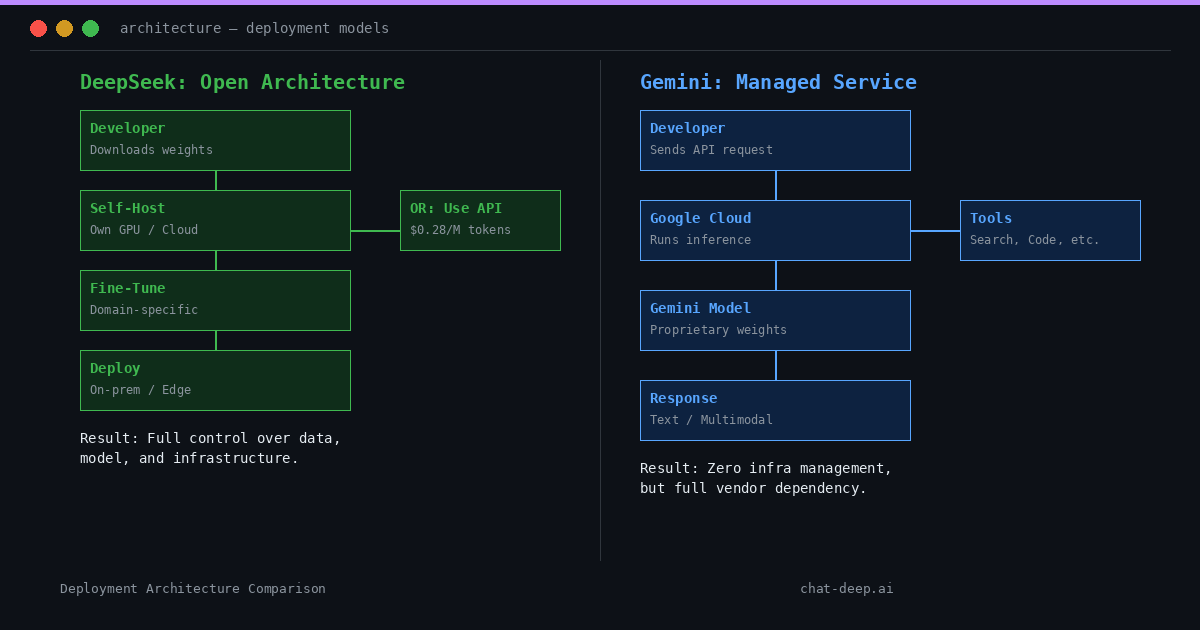
Open-Weight Deployment Model
DeepSeek provides open-weight releases as part of its ecosystem. The DeepSeek-R1 series is released under the MIT License, enabling developers to self-host and build on the model. For teams that prefer a managed option, DeepSeek also offers a cloud API service.
This open-weight vs. hosted distinction matters for deployment governance, data boundaries, and operational ownership. You can deploy DeepSeek on your own hardware or choose the convenience of the hosted API — the model is the same either way.
Dual Inference Modes: Chat and Reasoning
DeepSeek’s architecture features dual modes of operation for inference:
deepseek-chat— the default non-thinking mode, outputting answers directly. Optimized for general conversational and completion tasks.deepseek-reasoner— the reasoning-focused mode. Responses include a separatereasoning_contentfield containing intermediate reasoning tokens, alongside the final answer in thecontentfield.
This structured response format allows developers to programmatically retrieve and inspect the model’s thought process. For example, the reasoning_content might hold a breakdown of a math solution or logical steps in a problem, while content holds the final answer.
By separating reasoning from the answer, DeepSeek enables transparency. Users can see why the model answered the way it did — useful for debugging, verification, and educational purposes.
Function Calling and Tool Use
DeepSeek supports developer-defined function calling via its API. Developers define tools with JSON schemas, and the model can output structured JSON to invoke them. Both chat and reasoning modes support this.
Unlike managed services that execute tools server-side, DeepSeek’s approach is developer-mediated. You decide which tools to expose, and you handle execution. This provides granular control and security sandboxing.
Architecture Summary
In summary, DeepSeek’s architecture can be characterized by:
- Open, MIT-licensed model weights available for use, modification, and self-hosting
- A 685B-parameter MoE architecture with 37B active parameters per token
- 128K token context window with DSA for efficient long-context handling
- Unified inference modes — Chat for direct answers, Reasoner for transparent step-by-step solutions
- Transparent reasoning output via a structured
reasoning_contentfield - Both self-hosting and hosted API deployment options
Why DeepSeek’s Open-Weight Model Matters
Infrastructure Sovereignty
DeepSeek’s choice to release open-weight models has significant implications for control, flexibility, and transparency. By providing model weights openly, organizations can achieve infrastructure sovereignty over their AI deployments.
Users can run DeepSeek on-premises or in their private cloud, ensuring sensitive data and workloads remain under their control. No data is sent to an external API. This is crucial for industries with strict compliance requirements (GDPR, HIPAA, etc.), where an in-house deployment can be audited and secured within the company’s own environment.
In contrast to a fully managed service, an open-weight model means no cloud lock-in. There is no dependence on a specific vendor’s platform or pricing. DeepSeek’s documentation describes two practical paths: use the hosted API for convenience, or download weights and deploy in your own environment for maximum control.
For deployment and governance decisions, teams should evaluate the license terms, hosting architecture, and applicable policies to understand the exact boundaries of control and responsibility. Self-hosting gives you full sovereignty over data handling, but it also means you are responsible for maintaining uptime, applying updates, and enforcing usage policies.
Customization and Extensibility
Since the model weights are available, advanced users can fine-tune DeepSeek on domain-specific data or modify aspects of the model to better suit their applications. This is not possible with closed models like Gemini, whose parameters are proprietary.
With DeepSeek, an enterprise could fine-tune the model on its internal knowledge base, adjust behavior for a specific use case, or create a distilled version optimized for particular hardware. The MIT License grants full legal rights for these modifications. Community-created distilled versions already exist, demonstrating the ecosystem’s vitality and the practical value of open weights.
Even outputs generated by DeepSeek’s API are unrestricted. The company allows using API-generated content for further training or distillation, which is often prohibited by closed providers. This openness fosters a community of collaboration: external developers can build tooling around DeepSeek, share improvements, and audit the model for biases or weaknesses because the model internals are transparent.
One of DeepSeek’s defining features is this dual transparency — not only in the output reasoning it provides via the reasoning_content field, but also in that its training methods and weights are publicly documented and available for scrutiny. This level of openness is rare among frontier AI models.
Cost and Performance Control
Having an open-weight model translates to direct cost and performance control. Organizations can choose their hardware, optimize inference engines (vLLM, TensorRT-LLM), apply quantization, or scale horizontally — none of which is possible with API-only models.
DeepSeek’s API pricing is already among the most competitive in the market: $0.28 per million input tokens and $0.42 per million output tokens. Cached input tokens cost just $0.028/M — a 90% discount. Self-hosting can reduce costs further at scale, converting per-token fees into fixed infrastructure expenses.
For example, some users have run DeepSeek on custom clusters using optimized inference engines to serve large contexts efficiently at a fraction of API costs. Others have deployed smaller distilled versions on consumer-grade GPUs for specific use cases where full model capability is not needed.
None of this flexibility would be possible if the model were only available behind an API. In summary, DeepSeek’s open-weight approach gives users the power to decide how and where to use the AI. The model becomes a tool that the user owns in a practical sense, rather than just renting via API. In a field where many AI models are kept as proprietary assets, DeepSeek’s strategy of openness is a fundamental differentiator offering increased autonomy, auditability, and adaptability.
Where Gemini Differs From DeepSeek
While DeepSeek centers on openness and user-controlled deployment, Google Gemini takes a managed-model approach that differs in several structural ways.
Deployment: Managed Service vs. Open-Weight
According to Google’s documentation, Gemini models are provided as managed services through platforms such as the Gemini API and Vertex AI. Access is delivered via cloud-based endpoints, where model execution and scaling are handled within Google’s infrastructure.
The documentation focuses on API-based access and does not present downloadable model weights or self-hosted distributions for the Gemini Pro/Flash series. All inference runs on Google’s servers, meaning developers cannot run Gemini locally or in their own private cloud.
Google does offer the open-weight Gemma model family, including the newly released Gemma 4 under Apache 2.0. However, these are smaller, separate models — not the full Gemini Pro or Flash. Gemma 4 is purpose-built for on-device and edge deployment, activating only 2-4 billion parameters during inference, making it suitable for mobile and embedded use cases but not a substitute for the full Gemini Pro’s capabilities.
DeepSeek offers both hosted API access and open-weight releases of its full flagship model (V3.2 with 685B parameters). This structural difference means deployment governance, infrastructure control, and data handling depend entirely on which access model you select — and DeepSeek gives you that choice for the same frontier-class model.
Context Window Size
Google’s Gemini models feature massive context windows. The Gemini 3.1 Pro model supports up to 1,048,576 input tokens (approximately 1 million), with Gemini 2.5 Flash also supporting 1M token inputs.
DeepSeek’s V3.2 supports 128K tokens — an order of magnitude smaller. Practically, this means Gemini can handle use cases like analyzing an entire book or codebase in one request, where DeepSeek might need chunking or retrieval-augmented approaches.
However, utilizing 1M tokens has significant computational cost. Not all Gemini models offer this length (it’s a feature of Pro-tier models), and input costs double above 200K tokens on Gemini 3.1 Pro.
Multimodal Capabilities
Gemini models are designed as natively multimodal systems. According to Google’s documentation, Gemini supports inputs such as text, images, audio, video, and PDFs within the same model family. Certain variants also integrate image generation (Nano Banana 2), video generation (Veo 3.1), and speech synthesis.
DeepSeek’s primary hosted endpoints (deepseek-chat and deepseek-reasoner) are text-focused. Multimodal support is available through separate vision-language models like DeepSeek-VL, which require different configuration or endpoints.
As a result, Gemini offers a more integrated experience for workflows combining text with images, audio, or video. DeepSeek provides strong text reasoning and generation, with multimodal handled through dedicated model variants.
Integrated Tool Use and Agents
Google has built Gemini to be “agentic.” Within Google’s ecosystem, Gemini can execute code, perform Google Searches, retrieve documents, and use APIs during a conversation — all handled internally by Google’s infrastructure.
This is facilitated by Google’s AI Studio and Vertex AI platforms, which orchestrate tool calls behind the scenes. For example, you can ask Gemini a question that requires a web search, code execution, or data retrieval, and the model manages the entire process without additional developer intervention. As of March 2026, Gemini even supports combining built-in tools with custom function calling in a single API call.
DeepSeek supports function calling where the model outputs JSON indicating a tool name and arguments, and the developer’s system executes it. This requires the developer to define and handle those tools — parsing the model’s output, invoking external APIs, and feeding results back. The approach offers full control but demands more engineering effort.
Gemini’s tool usage is more native and extensive, reflecting its design as part of a larger agent ecosystem. DeepSeek provides the hooks for tool use but leaves implementation to the developer — which is preferable when you need security sandboxing or custom tool behavior that Google’s pre-built tools do not support.
Reasoning Exposure
DeepSeek’s reasoning endpoint returns a structured response separating intermediate reasoning from the final answer. The reasoning_content field contains reasoning tokens; the content field contains the answer. Developers can access and inspect the reasoning trace programmatically.
For example, when solving a complex math problem, the reasoning_content might show the model identifying the problem type, selecting an approach, working through intermediate calculations, catching and correcting errors, and arriving at the final answer. This level of visibility is invaluable for applications where explainability is a requirement, such as financial modeling, legal analysis, or educational tools.
Gemini takes a different approach. According to Google’s documentation, Gemini thinking models can optionally return thought summaries when the includeThoughts parameter is enabled. These are textual summaries of the model’s internal reasoning, not the raw reasoning tokens themselves.
Gemini also uses thought signatures — encrypted representations of internal reasoning state. These are designed to be passed back to the model in subsequent requests to preserve reasoning context in multi-step workflows. However, thought signatures are not human-readable explanations; they are opaque tokens for the model’s own use.
The structural difference is clear: DeepSeek returns reasoning tokens directly as part of the response schema in a dedicated field, making reasoning fully inspectable. Gemini provides summarized reasoning (when enabled) and maintains internal reasoning continuity through encrypted tokens. For developers who need full audit trails or want to debug reasoning step by step, DeepSeek’s approach offers significantly more granularity.
Gemini’s Evolving Model Lineup (March 2026)
Google’s Gemini ecosystem has evolved significantly. Here is the current state as of March 2026:
- Gemini 3.1 Pro (February 2026) — the current flagship, with major reasoning improvements over 3 Pro. Scored 77.1% on ARC-AGI-2, more than double the 31.1% posted by Gemini 3 Pro.
- Gemini 3.1 Deep Think — a specialized reasoning mode for complex science, research, and engineering problems. Available to Google AI Ultra subscribers.
- Gemini 3.1 Flash Lite (March 2026) — optimized for speed and cost efficiency. Budget-friendly for high-volume tasks.
- Gemini 2.5 Flash — remains available as the best price-performance model for low-latency tasks.
- Gemma 4 (April 2026) — Google’s open-weight model family under Apache 2.0, built from the same research as Gemini 3. Not Gemini Pro, but the most capable open model from Google.
Consumer plans include: Free (Gemini 3 Flash), Google AI Pro ($19.99/month with Gemini 3.1 Pro), and Google AI Ultra ($249.99/month with unlimited Deep Think and Veo 3.1 access).
Direct Structural Comparison Table
| Aspect | DeepSeek (V3.2) | Google Gemini (3.1 Pro) |
|---|---|---|
| Model Availability | Open-weight (MIT License). Can be self-hosted or used via API. | Proprietary managed service. Accessed through Gemini API and Vertex AI. No downloadable weights. |
| Deployment | On-premises, private cloud, or hosted API. Full infrastructure control. | Cloud-only via Google. Cannot run locally. |
| Parameters | 685B total / 37B active (MoE) | Not publicly disclosed |
| Context Window | 128K tokens | Up to 1,048,576 tokens (~1M) |
| Reasoning | Transparent chain-of-thought via reasoning_content field | Thought summaries (optional) + encrypted thought signatures |
| Multimodal | Text-focused. Separate vision models (DeepSeek-VL) available. | Native multimodal: text, images, audio, video, PDFs. Image/video generation via Nano Banana 2, Veo 3.1. |
| Tool Integration | Developer-mediated function calling (JSON output) | Native tools: code execution, Google Search, file search, grounding |
| Input Price (per M tokens) | $0.28 | $1.25 (≤200K), $2.50 (>200K) |
| Output Price (per M tokens) | $0.42 | $5.00 (≤200K), $10.00 (>200K) |
| Fine-Tuning | Full fine-tuning supported | Not available for Gemini. (Gemma 4 is fine-tunable.) |
| License | MIT (open) | Proprietary (Google ToS) |
DeepSeek prioritizes open deployment and reasoning transparency. Gemini is a closed, managed solution with broader multimodal and tool capabilities.
API Pricing Comparison
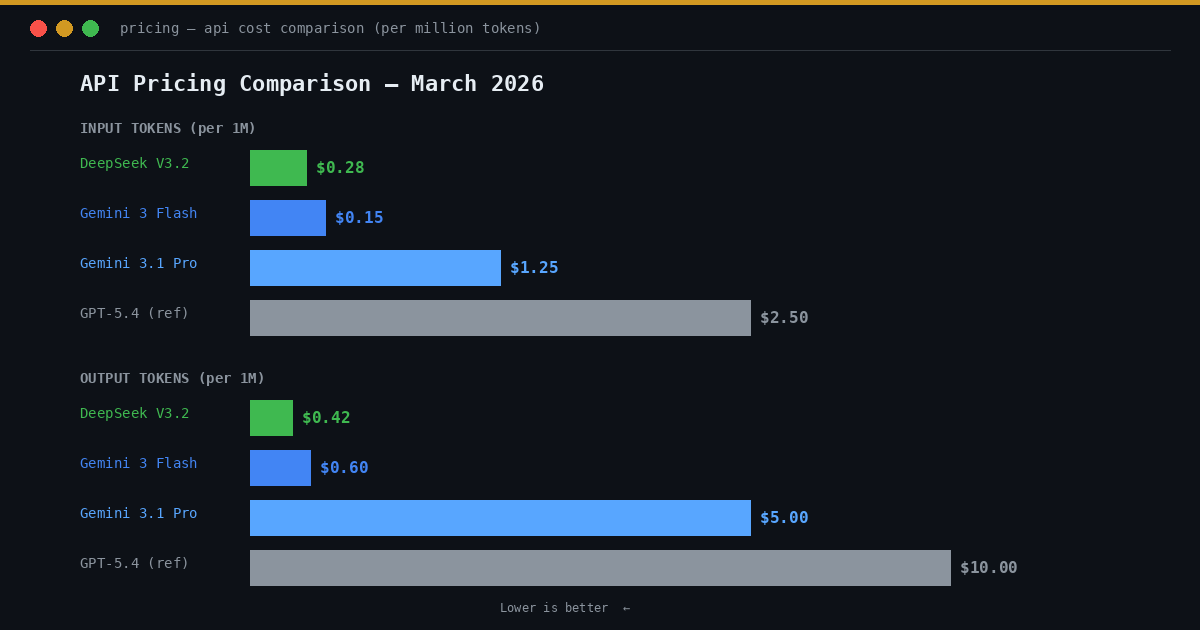
Pricing is a critical factor for production deployments. Here is a detailed breakdown as of March 2026:
| Model | Input (per M tokens) | Output (per M tokens) | Notes |
|---|---|---|---|
| DeepSeek V3.2 | $0.28 | $0.42 | Cached input: $0.028 (90% off) |
| Gemini 2.5 Flash | $0.15 | $0.60 | Budget option, lower capability |
| Gemini 3.1 Pro (≤200K) | $1.25 | $5.00 | Flagship. Doubles above 200K tokens. |
| Gemini 3.1 Pro (>200K) | $2.50 | $10.00 | Long-context premium pricing |
| GPT-5.4 (reference) | $2.50 | $10.00 | OpenAI flagship for comparison |
DeepSeek is 4-5x cheaper than Gemini 3.1 Pro on input and 12x cheaper on output. For long-context use above 200K tokens, Gemini’s pricing doubles, making DeepSeek’s cost advantage even more pronounced.
Self-hosting DeepSeek eliminates per-token fees entirely, converting costs to fixed infrastructure expenses. You can explore detailed cost projections with the DeepSeek API Cost Calculator.
Practical Use Case Considerations
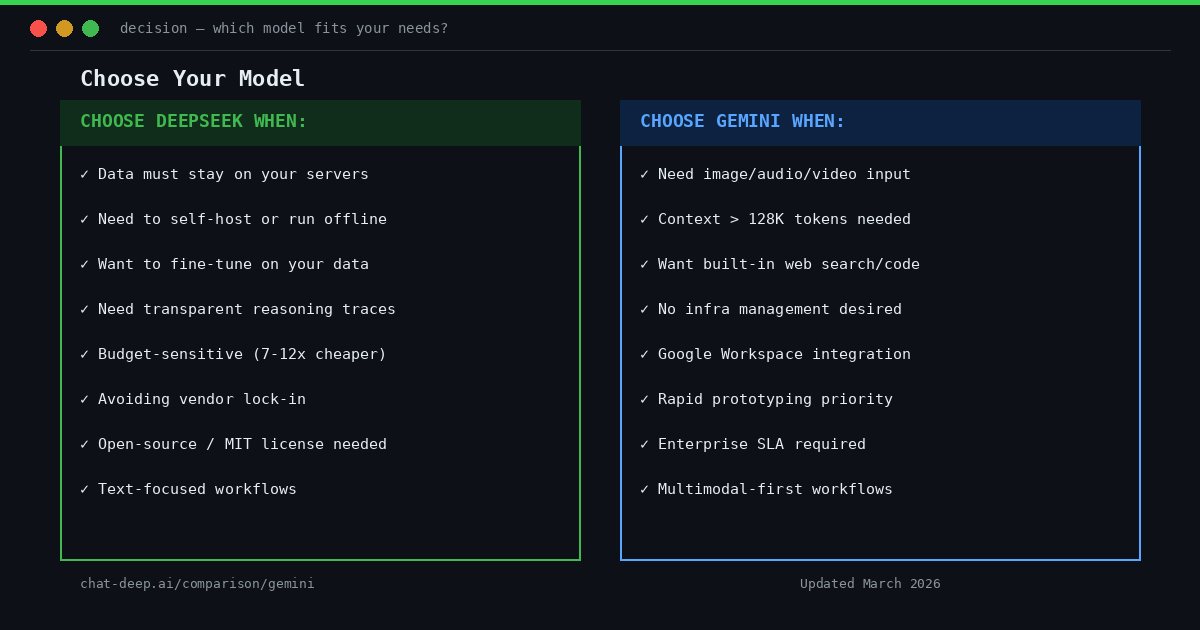
Both DeepSeek and Gemini are powerful platforms, but their structural differences mean each is better suited for different scenarios.
When DeepSeek’s Architecture Is Preferable
Data Privacy and Sovereignty: If you need to keep sensitive data in-house — financial, medical, or classified data — DeepSeek allows deployment on your own secure servers. Organizations with strict compliance requirements (GDPR, HIPAA) can avoid sending data to a third-party cloud entirely.
On-Premises or Edge Deployment: For use cases requiring AI in isolated environments — private corporate networks, edge devices, or regions with limited internet — DeepSeek’s open model can run offline without any external service dependency. Community tools for deploying with vLLM and similar frameworks make self-hosting increasingly accessible. You can spin up DeepSeek with an OpenAI-compatible API endpoint so existing applications can call it with minimal code changes. This is particularly valuable for defense, industrial IoT, and any environment where internet connectivity to an external API is infeasible or undesirable.
Transparent Reasoning and Auditing: In domains like scientific research, legal analysis, or education, examining the reasoning process is essential. DeepSeek’s reasoning_content field provides structured intermediate outputs, enabling developers to inspect how conclusions are formed and build audit trails for compliance.
Customization and Fine-Tuning: When you need to tailor the model to your domain — company-specific terminology, specialized technical language, or custom behavior — DeepSeek’s open weights enable full fine-tuning. You can also create distilled versions for specific hardware or modify the architecture itself.
Cost Control at Scale: DeepSeek’s API at $0.28/$0.42 per million tokens is dramatically cheaper than Gemini Pro at $1.25/$5.00 (and $2.50/$10.00 above 200K context). The pricing gap is 4-12x depending on the tier, and it widens further for long-context use cases where Gemini’s pricing doubles.
Self-hosting eliminates per-token costs entirely, converting expenses to fixed infrastructure. For high-volume applications processing millions of requests daily, the savings are transformative. Even on the API, DeepSeek’s 90% cache discount on repeated prefixes (system instructions, templates) can bring effective costs below $0.05 per million input tokens.
Avoiding Vendor Lock-in: Once you have DeepSeek’s weights, you can use them indefinitely regardless of what the vendor does. Changes in terms of service, pricing hikes, or service shutdowns do not affect your deployment. The model is released under the MIT License — one of the most permissive open-source licenses — with no usage restrictions beyond basic attribution.
For long-term projects requiring guaranteed continuity, this independence is a strong advantage. If you build your application tightly around Gemini’s API and Google later changes pricing, deprecates a model version, or alters terms of service, migration can be costly and disruptive. With DeepSeek, you control the entire lifecycle. You can also route tools like Claude Code through DeepSeek using its Anthropic-compatible API layer, providing additional integration flexibility.
If this analysis makes DeepSeek’s open-weight approach look like the better architectural fit, the next decision is which DeepSeek model you should actually deploy. Our DeepSeek model lineup guide compares the main families side by side so you can choose between general-purpose, reasoning-first, coding-first, and multimodal options.
When Gemini’s Ecosystem Is Preferable
Multimodal Tasks: If your application handles images, audio, or video alongside text, Gemini’s built-in multimodal capabilities are a major advantage. Building a chatbot that answers questions about images, or a digital assistant that parses PDFs and speaks answers aloud, is streamlined with Gemini’s one-stop model family. It can interpret an image or audio input directly without cobbling together separate vision or speech models. DeepSeek’s core chat endpoints are text-based; multimodal support through DeepSeek-VL requires separate configuration.
Ultra-Long Context: Tasks like processing entire books, huge code repositories, or lengthy transcripts may exceed DeepSeek’s 128K limit. Gemini’s 1M-token context can take in vastly more information at once — roughly equivalent to 800,000 words or thousands of pages.
For use cases pushing the boundaries of context size, such as analyzing massive log files, conducting in-depth literature review synthesis in a single prompt, or feeding an entire wiki into context, Gemini is structurally equipped where DeepSeek may need chunking, summarization, or retrieval-augmented generation approaches. However, be aware that Gemini’s pricing doubles above 200K tokens, making ultra-long contexts a premium feature.
Out-of-the-Box Tool Usage: When you want an AI agent that can execute code, search the web, and access databases with minimal development overhead, Gemini’s pre-integrated tools offer a faster path. You can ask Gemini a question that requires an action — like “What’s the weather in Paris?” which prompts a live search, or “Run this code and tell me the output” which triggers code execution — and the model handles it internally.
Achieving equivalent functionality with DeepSeek requires building a function-call loop: parsing the model’s JSON output, executing the tool, and feeding results back. For rapid development of AI assistants with internet and tool access, Gemini’s ecosystem is a faster route because those pieces are pre-integrated by Google.
Managed Infrastructure: Not every team has the means or desire to run a 37B-active-parameter model on their own hardware. Gemini abstracts away all DevOps complexity. Google ensures efficient serving, auto-scaling, and continuous model updates. For startups needing to ship AI features quickly, this reduces engineering overhead significantly.
You don’t need to worry about provisioning GPUs, optimizing model inference, or handling version updates. Google manages all of this behind the scenes, and you pay per token based on usage. For variable or unpredictable workloads, this elasticity is valuable — you scale costs with demand rather than maintaining fixed infrastructure.
Google Ecosystem Integration: If your use case already lives within Google Cloud, Workspace, or other Google products, Gemini integrates more seamlessly. Features like NotebookLM (for deep knowledge work with grounded sources), Gemini in Gmail and Docs, Android Auto integration, and Vertex AI’s data tools create a cohesive ecosystem that no independent model can match.
Google has also introduced features like Custom Gems (shareable AI personas), Gemini in Android Auto for hands-free assistance, and Project Mariner (browser automation for Ultra subscribers). For companies deeply embedded in Google’s stack, using Gemini reduces friction and enables workflows that span multiple Google products. DeepSeek, being independent, does not have these platform-specific integrations.
Continual Improvements: Because Gemini is maintained by Google, you automatically benefit from model upgrades and safety improvements. When Google released Gemini 3.1 Pro with doubled ARC-AGI-2 scores, it became available via API immediately. No action was required from developers. Similarly, when the Gemini 3 Pro Preview was deprecated on March 9, 2026, migration to 3.1 Pro was handled with minimal disruption for most API users.
With self-hosted DeepSeek, you would need to manually obtain and deploy any new model version. This gives you control over when and whether to upgrade, but it also means you need to actively manage the lifecycle. Google’s managed approach ensures you are always on the latest, most capable version — which is a significant advantage for teams that want cutting-edge performance without operational overhead.
Additionally, Google offers enterprise-grade support with SLA-backed reliability, which may be required for mission-critical applications. This level of accountability comes naturally with a Google Cloud service like Gemini, whereas self-hosted DeepSeek deployments rely on your own team’s operational capabilities.
In summary, choose DeepSeek when you need maximum control, transparency, and flexibility. Opt for Gemini when you need a broad, turnkey AI solution with multimodal understanding, massive context, and rich tool integrations — and you’re comfortable with a fully cloud-based service.
Conclusion
DeepSeek and Google Gemini exemplify two fundamentally different philosophies in the AI model landscape.
DeepSeek’s approach is centered on openness and user empowerment. It gives practitioners the ability to own the model — to host it, inspect it, and adapt it. This leads to greater transparency (with exposed reasoning chains) and independence (no vendor dependency). With V3.2’s unified reasoning, gold-medal benchmarks, and pricing at a fraction of competitors, DeepSeek is compelling for teams who value autonomy.
Gemini’s approach offers AI as a managed, feature-rich service. It hides complexity behind a convenient API while integrating tightly with Google’s ecosystem of data, tools, and multimodal capabilities. With 3.1 Pro’s massive context window, Deep Think reasoning, and native support for text, images, audio, and video, Gemini is powerful for teams who want breadth and convenience.
Neither approach is strictly “better” in all contexts — each involves trade-offs. DeepSeek’s open-weight releases offer greater deployment flexibility, reasoning transparency, and cost control, though they require infrastructure management and separate components for multimodal use cases. Gemini’s managed platform provides an integrated environment with multimodal capabilities, extended context windows, and built-in tooling, while operating as a hosted service with limited visibility into internal reasoning.
The choice depends on governance preferences, technical requirements, deployment strategy, and budget constraints. Many organizations may find that different projects within the same company benefit from different models — using DeepSeek for privacy-sensitive, cost-critical, or custom workloads while leveraging Gemini for multimodal or ecosystem-integrated use cases.
For organizations prioritizing architectural flexibility, deployment control, and cost efficiency, DeepSeek is a strong fit. For teams valuing integrated multimodal capabilities, managed infrastructure, and ecosystem-level tooling, Gemini offers a compelling package within Google’s platform.
The emergence of this diversity is a healthy sign: developers can now choose between an open model they fully control and a managed model packaged with powerful extras. For more on DeepSeek’s capabilities, explore our API documentation, chat interface, and model guides.
Disclosure: This article is provided by an independent informational site and is not affiliated with DeepSeek or Google. All observations are based on publicly available documentation.
Frequently Asked Questions
Is DeepSeek free to use?
DeepSeek’s open-weight models can be downloaded and self-hosted at no licensing cost under the MIT License. The official API offers a free tier with 5 million tokens on signup, after which pricing starts at $0.28 per million input tokens. The web chat interface is also free with usage limits.
Is Google Gemini free to use?
The Gemini chatbot offers a free tier with access to Gemini 3 Flash. Google AI Pro costs $19.99/month for Gemini 3.1 Pro access, and Google AI Ultra costs $249.99/month for unlimited Deep Think and premium features. API pricing starts at $0.15/M input tokens for Flash and $1.25/M for Pro.
Can I self-host Gemini?
No. Gemini Pro and Flash models are proprietary and only available through Google’s managed API. Google does offer the open-weight Gemma model family (including the new Gemma 4 under Apache 2.0), but these are smaller, separate models — not the full Gemini Pro. DeepSeek is the self-hostable frontier model in this comparison.
Which model has a larger context window?
Gemini 3.1 Pro supports up to 1,048,576 tokens (~1M), while DeepSeek V3.2 supports 128K tokens. Gemini’s context is roughly 8x larger. However, Gemini’s pricing doubles above 200K tokens, and most practical applications work well within DeepSeek’s 128K limit.
Which is better for coding?
DeepSeek V3.2 achieved gold-medal results on the 2025 IOI (International Olympiad in Informatics) and supports transparent reasoning for debugging. Gemini 3.1 Pro also excels at coding with strong agentic capabilities and code execution tools. DeepSeek is preferred when you need reasoning transparency and cost efficiency; Gemini is preferred when you need integrated code execution and massive context for large codebases.
What is Gemma 4 and how does it relate to Gemini?
Gemma 4, released April 2026, is Google’s open-weight model family built from the same research as Gemini 3. It is released under the Apache 2.0 license and can be self-hosted. However, Gemma models are smaller and less capable than the full Gemini Pro/Flash models. Think of Gemma as the open-source sibling of Gemini — powerful for its size, but not a direct replacement for the managed Gemini service.


